Firstly, I will copy the original dataset to other object. I think it’s a good habit because sometime you code wrong leading to wrong result and you want to run again but the previous object is changed to new one and you have to import the data again. It’s not smooth.
So adjusting the data to standardize form to suitable for coding in R. Remember df have a column refer to datetime class, you should divide into 2 cols: date and time cols separately. You should download this data procurement_data before.
Code
## Copy into new object:df<-procurement_data ## Adjusting:df<-df %>%# standardize column name syntax janitor::clean_names() %>%distinct() df <- df %>%# break the datetime PO into date and time cols separatelymutate(po_date =as.Date(df$po_date_time),po_time =hms(format(df$po_date_time,"%H:%M:%S")))df$money<-runif(nrow(df),1000,10000)
ABC analyst:
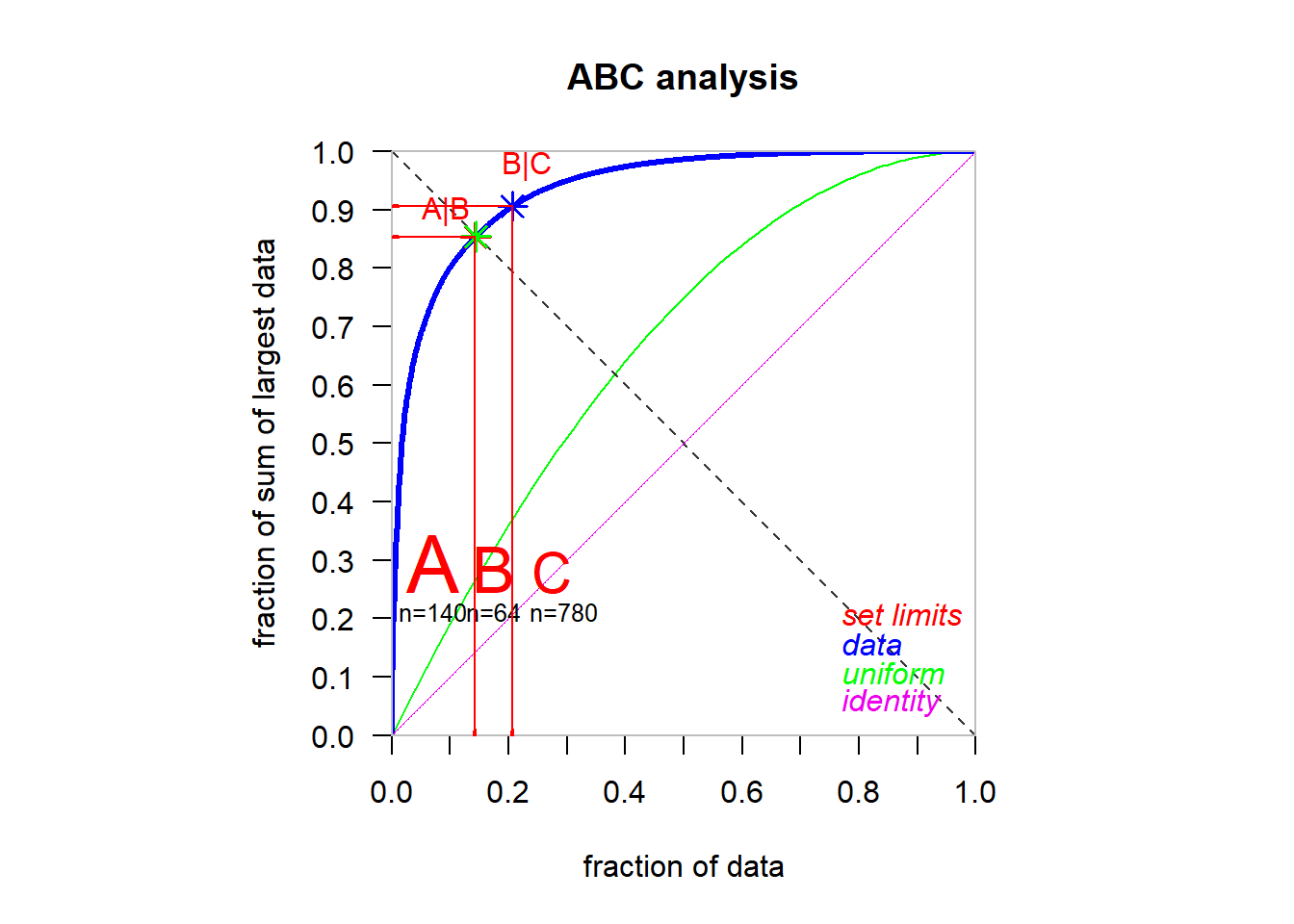
In supply chain management, you typically faces the task of ABC analysis to classify your major customers by comparing their revenue or purchase frequency. So to impelemnt this task, I create a data contains the vendor’s name and the total revenue caculated by the amount of PO sign the total value of PO.
In R, we have package {ABCanalysis} to encounter this task by simply one function: ABCanalysis showed below.
Code
# Sum total PO of each vendor:ABC<-df %>%group_by(vendor_name) %>%summarise(revenue =round(sum(po_amount * money)/10^3,0))library(ABCanalysis)abc =ABCanalysis(ABC$revenue,PlotIt=TRUE)
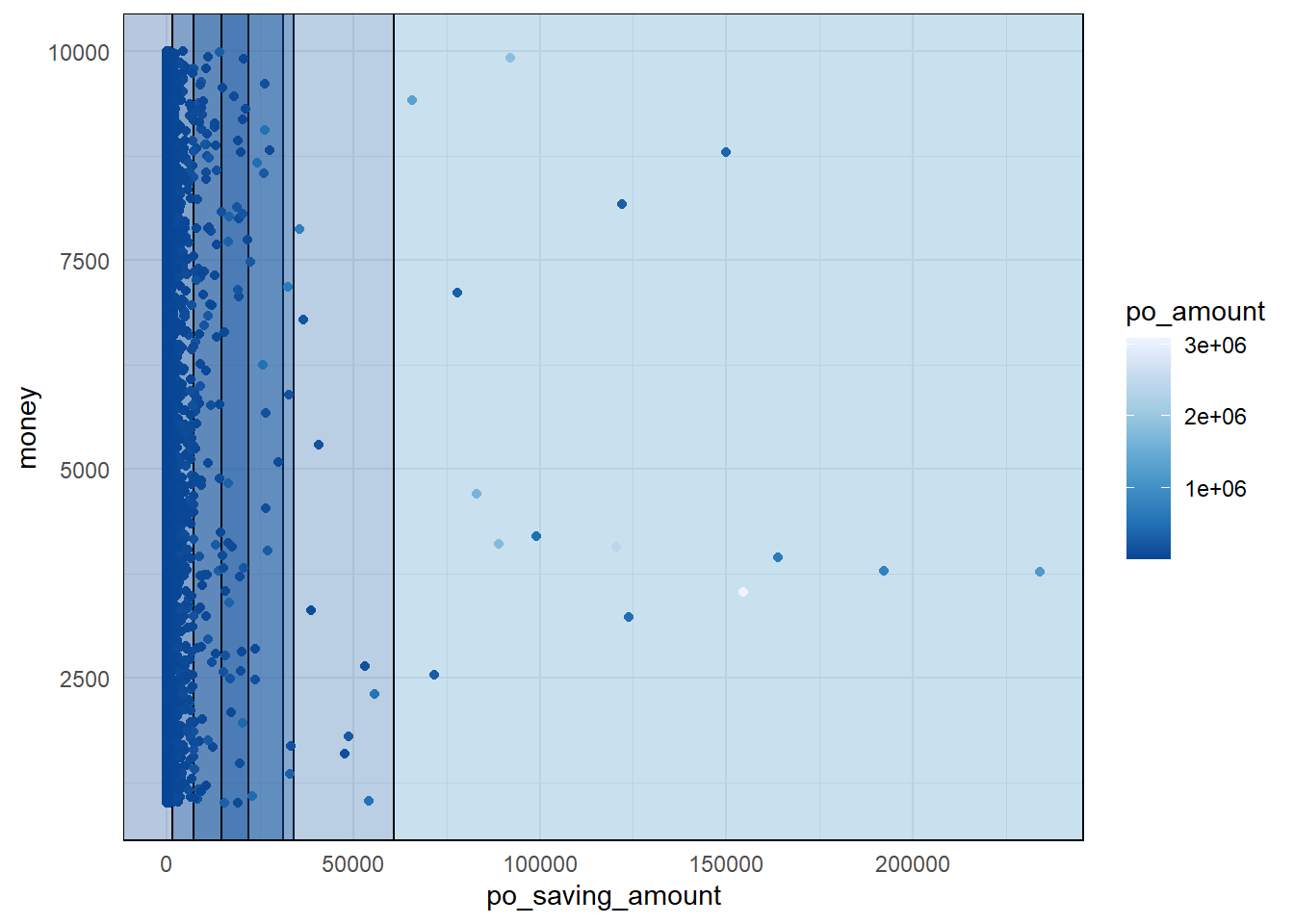
Now we have classified all the companies on our list, but we need to be prepared for any future collaborations. When considering collab with a new company, we will need to know which classification it falls under in order to decide whether to sign a long-term contract. In this section, I’d like to introduce the Random Forests method, a machine learning algorithm that combines the outputs of multiple decision trees to produce a single result. For more details, you can refer to this page: Random Forest
In R, we can easily implement this using the following code. It’s important to note a few things:
The rpart function has default parameters that can limit the growth of the tree, so we should consider adjusting them. For example:
The argument “minsplit” represents the minimum number of observations required in a node for a split to be attempted.
The argument “minbucket” represents the minimum number of observations in any terminal node. We should observe the impact of overriding these parameters.
Package {parttree} maybe not avaliable in your Rstudio version. You can update your version or directly install from online source by function remote::install_github("https://github.com/grantmcdermott/parttree")
The cluster of customer group based on the total PO amount
Next we will move to the next section is about: Report concepts
Source Code
---title: "ABC analyst concepts"format: html: code-fold: true code-tools: true---So let's pratice !!!Firstly, I will copy the original dataset to other object. I think it's a good habit because sometime you code wrong leading to wrong result and you want to run again but the previous object is changed to new one and you have to import the data again. It's not smooth.So adjusting the data to standardize form to suitable for coding in R. Remember **df** have a column refer to datetime class, you should divide into 2 cols: date and time cols separately. You should download this data [procurement_data](index.qmd) before.```{r}#| include: falselibrary(readxl)procurement_data <-read_excel(r"(C:/Users/locca/Documents/Xuân Lộc/VILAS/Data_Chuong 7/procurement_data.xlsx)")## Call packages:pacman::p_load(rio, here, janitor, tidyverse, dplyr, magrittr, ggplot2, purrr, lubridate, knitr, shiny)``````{r}## Copy into new object:df<-procurement_data ## Adjusting:df<-df %>%# standardize column name syntax janitor::clean_names() %>%distinct() df <- df %>%# break the datetime PO into date and time cols separatelymutate(po_date =as.Date(df$po_date_time),po_time =hms(format(df$po_date_time,"%H:%M:%S")))df$money<-runif(nrow(df),1000,10000)```## ABC analyst: In supply chain management, you typically faces the task of ABC analysis to classify your major customers by comparing their revenue or purchase frequency. So to impelemnt this task, I create a data contains the vendor's name and the total revenue caculated by the amount of PO sign the total value of PO. In R, we have package `{ABCanalysis}` to encounter this task by simply one function: `ABCanalysis` showed below.```{r}#| warning: false#| message: false # Sum total PO of each vendor:ABC<-df %>%group_by(vendor_name) %>%summarise(revenue =round(sum(po_amount * money)/10^3,0))library(ABCanalysis)abc =ABCanalysis(ABC$revenue,PlotIt=TRUE)setA = ABC$revenue[abc$Aind]setB = ABC$revenue[abc$Bind]setC = ABC$revenue[abc$Cind]abc.df<-cbind(c(setA,setB,setC),c(rep("A",length(setA)),rep("B",length(setB)),rep("C",length(setC)))) %>%as.data.frame() colnames(abc.df)<-c("revenue","group")abc.df$revenue<-as.numeric(abc.df$revenue)ABC<-left_join(abc.df, ABC,by ="revenue")``` Although it's result is accurate but I don't like the default plot because it's too ugly and color is terrible. So I suggest another package `{gt}` in R help us a lot to present fancy result.```{r}#| warning: false#| message: false#| layout-ncol: 2# Finally plot the result:A<-ABC %>%filter(group =="A") %>%select(3,1,2)library(gt)library(gtExtras)gt(A[order(A$revenue,decreasing =TRUE),][1:68,]) %>%#Reorder the column in datacols_label(vendor_name =md("**Name of vendor**"),group ="Class",revenue =md("**Total revenue**")) %>%tab_header(title =md("Result of ABC analyst"),subtitle =md("Source: Xuan Loc, Rstudio") ) %>%cols_align(align ="left",columns ="vendor_name" ) %>%cols_align(align ="center",columns ="revenue" ) %>%fmt_number(columns ='revenue', decimals =2, locale ='de',pattern ='{x}$' ) %>%grand_summary_rows(columns = revenue,fns =list(total =~sum(., na.rm =TRUE),avg =~mean(., na.rm =TRUE),s.d. =~sd(., na.rm =TRUE)),fmt =list(~fmt_currency(.,suffixing =TRUE,locale =list(decimals =3,locale ="fr_BE",curency ="USD")$locale))) %>%tab_options(data_row.padding =px(0),summary_row.padding=px(0),row_group.padding =px(0),column_labels.padding =px(1),heading.padding =px(1)) %>%gt_theme_excel()gt(A[order(A$revenue,decreasing =TRUE),][69:137,]) %>%#Reorder the column in datacols_label(vendor_name =md("**Name of vendor**"),group ="Class",revenue =md("**Total revenue**")) %>%tab_header(title =md("Result of ABC analyst"),subtitle =md("Source: Xuan Loc, Rstudio") ) %>%cols_align(align ="left",columns ="vendor_name" ) %>%cols_align(align ="center",columns ="revenue" ) %>%fmt_number(columns ='revenue', decimals =2, locale ='de',pattern ='{x}$' ) %>%grand_summary_rows(columns = revenue,fns =list(total =~sum(., na.rm =TRUE),avg =~mean(., na.rm =TRUE),s.d. =~sd(., na.rm =TRUE)),fmt =list(~fmt_currency(.,suffixing =TRUE,locale =list(decimals =3,locale ="fr_BE",curency ="USD")$locale))) %>%tab_options(data_row.padding =px(0),summary_row.padding=px(0),row_group.padding =px(0),column_labels.padding =px(1),heading.padding =px(1)) %>%gt_theme_excel()```Now we have classified all the companies on our list, but we need to be prepared for any future collaborations. When considering collab with a new company, we will need to know which classification it falls under in order to decide whether to sign a long-term contract. In this section, I'd like to introduce the Random Forests method, a machine learning algorithm that combines the outputs of multiple decision trees to produce a single result. For more details, you can refer to this page: [Random Forest](https://www.gormanalysis.com/blog/decision-trees-in-r-using-rpart/)In R, we can easily implement this using the following code. It's important to note a few things:- The rpart function has default parameters that can limit the growth of the tree, so we should consider adjusting them. For example: - The argument "minsplit" represents the minimum number of observations required in a node for a split to be attempted. - The argument "minbucket" represents the minimum number of observations in any terminal node. We should observe the impact of overriding these parameters.- Package {parttree} maybe not avaliable in your Rstudio version. You can update your version or directly install from online source by function `remote::install_github("https://github.com/grantmcdermott/parttree")````{r}#| warning: false#| fig-cap: "The cluster of customer group based on the total PO amount"df1<-left_join(ABC %>%select(c(vendor_name, group)), df,by ="vendor_name")library(rpart)library(parttree)tree<-rpart(po_amount ~ po_saving_amount + money, data = df1)ggplot(data = df1,aes(x = po_saving_amount,y = money))+geom_parttree(data = tree,aes(fill = po_amount),alpha =0.3)+geom_point(aes(col = po_amount))+theme_minimal() +scale_fill_distiller(limits =range(df1$po_amount, na.rm =TRUE), aesthetics =c('colour', 'fill') )```Next we will move to the next section is about: [Report concepts](reactable.qmd)