Ở đây ta sẽ học về mô hình machine learning được ứng dụng nhiều nhất trong việc phân tích dữ liệu thời gian là RNN và LSTM.
1 Mô hình RNN:
1.1 Định nghĩa:
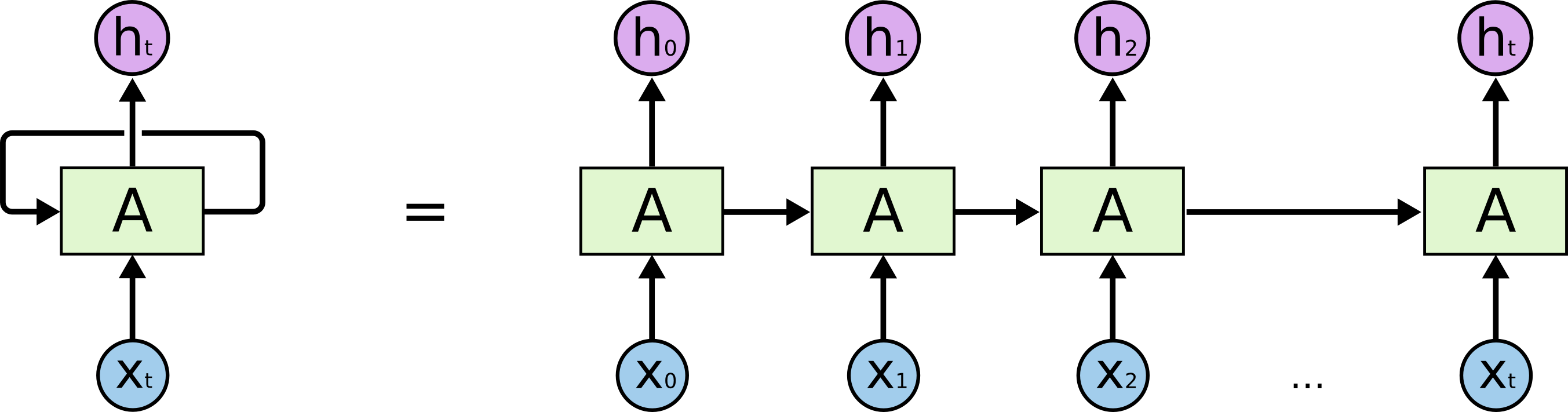
Điểm chung là cả hai mô hình đều thuộc phân lớp Deep learning - nghĩa là học máy sâu với đặc điểm chung là phân chia dữ liệu thành nhiều lớp và bắt đầu “học” dần qua từng lớp để đưa ra kết quả cuối cùng. Ở hình dưới đây, \(X_o\) đại diện cho dữ liệu đầu vào, \(h_t\) là output đầu ra của từng step và \(A\) là những gì đã “học” được tại step đó và được truyền cho step tiếp theo. Trong tài liệu chuẩn thì họ thường kí hiệu là \(X_t\), \(Y_t\), \(h_{t-1}\).
Hình 1: Minh họa về sự phân chia dữ liệu thành nhiều lớp
Khi nhìn hình thì bạn có thể bối rối chưa hiểu các kí tự và hình ảnh thì bạn có thể tưởng tượng học máy như 1 đứa trẻ và để nó có thể hiểu được câu: “Hôm nay con đi học” thì nó phải học từng chữ cái như: a,b,c,… trước ròi mới ghép thành từ đơn như: “Hôm”,“Nay”,… rồi ghép thành câu trên.
Vậy giả sử như hôm nay học được từ “Hôm” thì nó sẽ bắt đầu ghi nhớ từ đã học vào trong \(A\). Nếu sau này ta cần học máy hiểu câu “Hôm sau con đi chơi” thì tốc độ học của học máy sẽ nhanh lên vì thay vì nó phải học 5 chữ đơn như thông thường thì nó chỉ cần học 4 chữ còn lại trừ chữ “hôm”. Vậy bạn đã hiểu ý tưởng nền tảng của RNN rồi ha!
1.2 Nguyên lí hoạt động:
Đầu tiên, RNN sẽ tính toán hidden state là \(h_t\) với công thức là:
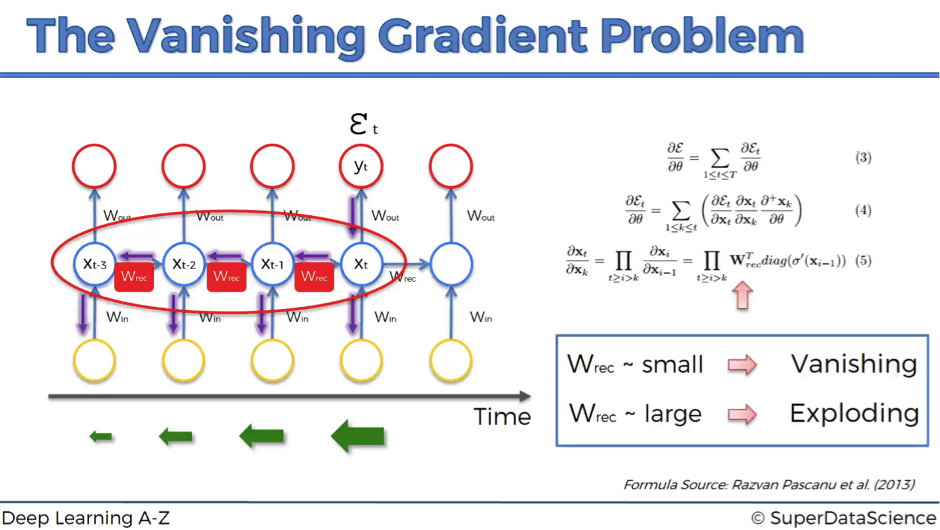
RNN có 1 vấn đề lớn là Vanishing Gradient nghĩa là mô hình sẽ không còn “học” thêm được nữa cho dù tăng số epochs. Nguyên nhân vì sao như vậy thì bạn có thể tham khảo phần chứng minh của anh Tuấn.
Vấn đề này sẽ làm network khó update weight dẫn tới thời gian học lâu và khó để đạt được output. Bạn có thể hiểu đơn giản như việc bạn học liên tục dẫn tới quá tải và RNN cũng không như vậy. Do đó, RNN chỉ học các thông tin từ state gần và đó là lí do ra đời LSTM - Long short term memory.
Warning
Lưu ý: Điều này không có nghĩa LSTM luôn tốt hơn RNN vì có những bài toán với đầu vào đơn giản thì mô hình chỉ cần học các step đầu là đã “học” đầy đủ thông tin cần thiết. Mô hình LSTM phổ biến với các bài toán phức tạp như tự động dịch ngôn ngữ, ghi chép lại theo giọng nói…
1.4 Mô hình LSTM:
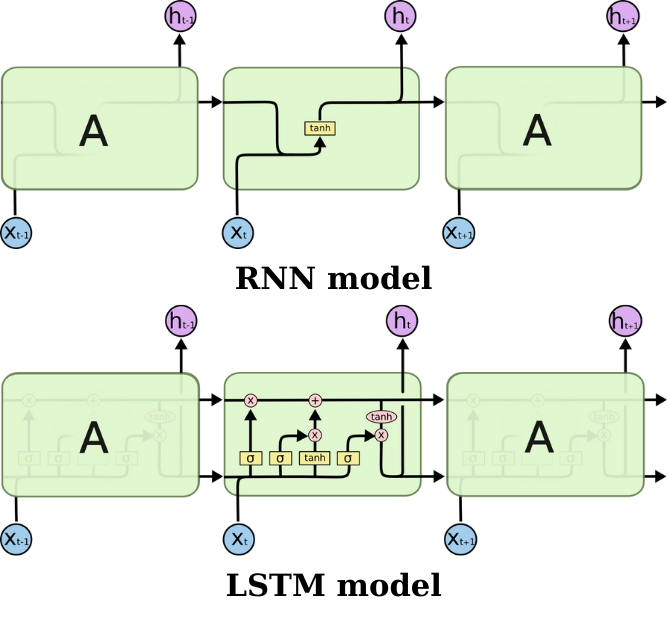
Có thể xem mô hình LSTM như biến thể của RNN. Về cấu trúc, LSTM phức tạp hơn RNN:
Cổng quên (Forget Gate): có tác dụng quyết định thông tin nào cần bị quên trong trạng thái ô nhớ.
Cổng nhập (Input Gate): Xác định thông tin nào cần được ghi vào trạng thái ô nhớ.
Cổng xuất (Output Gate): Quyết định thông tin nào sẽ được xuất ra từ trạng thái ô nhớ để ảnh hưởng đến dự đoán tiếp theo.
Bạn có thể kham khảo thêm bài viết của dominhhai về cách hoạt động của RNN và LSTM để hiểu thêm.
Tiếp theo, ta sẽ bắt đầu xây dựng thử mô hình trong R.
2 Xây dựng mô hình:
2.1 Load dữ liệu:
Đầu tiên ta sẽ load dữ liệu lại như trước. Ở đây, để đơn giản, mình chỉ xây dựng mô hình cho product A thôi.
Giả sử công ty mình đang kinh doanh 3 loại mặt hàng product A,product B,product C và đây là biểu đồ thể hiện nhu cầu của cả 3 mặt hàng từ tháng 5 tới tháng 10.
Code
library(highcharter)sales_data |>select(-Weekday) |>pivot_longer(cols =c(Product_A, Product_B, Product_C),names_to ="Product",values_to ="Sales") |>hchart("line", hcaes(x = Date, y = Sales, group = Product))
Nếu ta phân tich sâu về nhu cầu của từng mặt hàng theo thứ trong tuần, ta sẽ thấy rằng mặt hàng A, B thì bán chạy vào thứ 4 và thứ 7, còn mặt hàng C thì bán chạy vào thứ 2 và thứ 3.
Thông thường dữ liệu để train model trong machine learning thường cần trải qua bước normalize data nghĩa là đưa tất cả dữ liệu về chung 1 thước đo và phạm vi. Nguyên do vì điều này giúp nhiều thuật toán học máy dễ dàng hội tụ hơn. Ví dụ, các thuật toán như k-Nearest Neighbors (KNN) và Support Vector Machines (SVM) rất nhạy cảm với khoảng cách giữa các điểm dữ liệu nên nếu dữ liệu không được chuẩn hóa, thuật toán có thể ưu tiên các đặc trưng có phạm vi lớn hơn và bỏ qua các đặc trưng có phạm vi nhỏ hơn, dẫn đến hiệu suất kém. Và công thức phổ biến nhất cho chuẩn hóa là:
# Create a data frame with the adjusted sales datasales_data <-data.frame(Date = dates,Weekday = weekdays,Product_A = product_a_sales,Product_B = product_b_sales,Product_C = product_c_sales)# Convert the sales data to a time series (ts) object for Product Aproduct_a_ts <-ts(sales_data$Product_A, start =c(2024, 5), frequency =365)# Normalzie data:time_series_data<-scale(product_a_ts)library(highcharter)highchart() |>hc_add_series(data =as.numeric(time_series_data), type ="line", name ="Sales of Product A") |>hc_title(text ="Normalized Time Series of Product A") |>hc_xAxis(title =list(text ="Date")) |>hc_yAxis(title =list(text ="Normalized Sales")) |>hc_tooltip(shared =TRUE) |>hc_plotOptions(line =list(marker =list(enabled =FALSE)))
2.2 Chia dữ liệu:
Vậy để train data, mình sẽ chia bộ dữ liệu thành 3 phần:
Training data: dùng để huấn luyện và xây dựng mô hình.
Evaluating data: đánh giá mô hình vừa huấn luyện.
Testing data: dùng để đánh giá lại nếu muốn mô hình học lại dữ liệu
Code
sales_data <-data.frame(Date = dates,Weekday = weekdays,Product_A = product_a_sales,Product_B = product_b_sales,Product_C = product_c_sales)# Convert the sales data to a time series (ts) object for Product Atime_series_data <-scale(ts(sales_data$Product_A, start =c(2024, 5), frequency =365))create_supervised_data <-function(series, n) { series <-as.vector(series) # Convert time series object to vector data <-data.frame(series) # Initialize data frame with the original series# Create lag columnsfor (i in1:n) { lagged_column <-lag(series, i) # Get lagged values data <-cbind(data, lagged_column) # Add lagged column to the data }# Name the columns properlycolnames(data) <-c(paste0('t-', n:1), 't+1')# Remove rows with NA values (those at the start of the series due to lagging) data <-na.omit(data)return(data)}# Prepare the data with 12 input lags and 1 output (next time step)supervised_data <-create_supervised_data(time_series_data,n =50)# Step 2: Split data into training and test setstrain_size <-round(0.7*nrow(supervised_data)) # 70% for trainingval_size <-round(0.1*nrow(supervised_data)) # 10% for validationtest_size <-nrow(supervised_data) - train_size - val_size # 20% for testingtrain_data <- supervised_data[1:train_size, ]val_data <- supervised_data[(train_size +1):(train_size + val_size), ]test_data <- supervised_data[(train_size + val_size +1):nrow(supervised_data), ]# Correct column selectionx_train <-as.matrix(train_data[, 1:50]) # Input features (12 lags)y_train <-as.matrix(train_data[, 't+1']) # Target output (next time step)x_val <-as.matrix(val_data[, 1:50]) # Input features for validationy_val <-as.matrix(val_data[, 't+1']) # Actual output for validationx_test <-as.matrix(test_data[, 1:50]) # Input features for testingy_test <-as.matrix(test_data[, 't+1']) # Actual output for testing## Plot the result:library(xts)n<-quantile(sales_data$Date, probs =c(0, 0.7, 0.8,1), type =1)m1<-sales_data |>filter(Date <= n[[2]])m2<-sales_data |>filter(Date <= n[[3]] & Date > n[[2]])m3<-sales_data |>filter(Date <= n[[4]] & Date > n[[3]])demand_training<-xts(x=m1$Product_A,order.by=m1$Date)demand_testing<-xts(x=m2$Product_A,order.by=m2$Date)demand_forecasting<-xts(x=m3$Product_A,order.by=m3$Date)library(dygraphs)lines<-cbind(demand_training, demand_testing, demand_forecasting)dygraph(lines,main ="Training and testing data", ylab ="Quantity order (Unit: Millions)") |>dySeries("demand_training", label ="Training data") |>dySeries("demand_testing", label ="Testing data") |>dySeries("demand_forecasting", label ="Forecasting data") |>dyOptions(fillGraph =TRUE, fillAlpha =0.4) |>dyRangeSelector(height =20)
2.3 Mô hình RNN:
Sau đó, ta sẽ bắt đầu train model bằng cách tạo thêm 12 cột giá trị là giá trị quá khứ của demand. Bạn sẽ bắt đầu định nghĩa mô hình gồm:
Input: dùng hàm layer_input(shape = input_shape) với input_shape là số lượng predictor.
Layer: là các hidden layer trong mô hình thêm vào bằng hàm layer_dense(x, units = 64, activation = 'relu') với đối số units thường là bội số của 32 như 32,64,256,…
Output: dùng hàm layer_dense(x, units = 1) để định nghĩa là đầu ra chỉ có 1 giá trị.
Đối với các mô hình truyền thống như linear regression thì bạn đã quen với thông số \(R^2\) để đánh giá mô hình, còn với mô hình Machine learning thì dùng khái niệm loss function - hàm mất mát. Về khái niệm, loss function sẽ đo lường chênh lệch giữa predicted và actual trong bộ training data nên khi càng tăng epochs nghĩa là tăng số lần học lại dữ liệu thì loss function sẽ tính ra giá trị càng thấp. Như mô hình trên thì mình đặt đối số loss = mse nghĩa là sử dụng Mean Squared Error để tối ưu quy trình học của học máy. Công thức như sau:
Còn đối số metrics = c('mae') nghĩa là tiêu chí khác để theo dõi và đánh giá mô hình. Vậy tại sao cần có 2 tham số đánh giá song song như vậy là vì như đã nói, nếu bạn càng tăng epochs thì giá trị loss càng thấp trong khi dùng metrics sẽ đưa ra đánh giá khách quan hơn về mô hình mà không phụ thuộc vào số lần epochs. Công thức như sau:
Vậy khi chạy code, R sẽ return output như biểu đồ dưới đây là so sánh tham số của mse và mae giữa training data và evaluating data. Ý tưởng là đánh giá thử mô hình có dự đoán tốt không khi có dữ liệu mới vào.
Tiếp theo, ta sẽ dùng test data để đánh giá mô hình vừa xây dựng. Kết quả có vẻ khá ổn vì mô hình gần như theo sát được dữ liệu của test data.
Code
# Step 6: Make predictionsRNN_forecast <- RNN_model |>predict(x_test)
1/1 - 0s - 291ms/step
Code
# Step 7: Combine predicted and observedplot_data <-data.frame(actual = y_test, # Actual values from the test setforecast = RNN_forecast # Forecasted values)# Step 8: Plot using Highchartshighchart() |>hc_title(text ="Time Series Forecasting with Highcharts") |>hc_xAxis(categories = plot_data$time,title =list(text ="Time") ) |>hc_yAxis(title =list(text ="Value"),plotLines =list(list(value =0,width =1,color ="gray" )) ) |>hc_add_series(name ="Actual Data",data = plot_data$actual,type ="line",color ="#1f77b4"# Blue color for actual data ) |>hc_add_series(name ="Forecast",data = plot_data$forecast,type ="line",color ="#ff7f0e"# Orange color for forecast data ) |>hc_tooltip(shared =TRUE,crosshairs =TRUE ) |>hc_legend(enabled =TRUE )
2.4 Mô hình LSTM:
Tiếp theo, ta sẽ xây dựng thử mô hình LSTM. Mô hình LSTM thường bao gồm các lớp sau:
Lớp LSTM: Đây là lớp chính, có thể có một hoặc nhiều lớp LSTM chồng lên nhau. Mỗi lớp LSTM có thể trả về toàn bộ chuỗi bằng return_sequences = TRUE hoặc chỉ trả về giá trị cuối cùng bằng return_sequences = FALSE.
Lớp Dense: Sau khi thông tin được xử lý qua các lớp LSTM, nó sẽ được đưa qua các lớp Dense (lớp fully connected) để đưa ra dự đoán cuối cùng.
Lớp Dropout (tùy chọn): Để tránh overfitting, có thể thêm lớp dropout để tắt ngẫu nhiên một số nơ-ron trong quá trình huấn luyện.
Vậy giờ ta sẽ so sánh với mô hình RNN trước với mô hình LSTM qua 2 thông số đã chọn mse và mae.
Code
# Extract metrics into a data frameresults_df <-data.frame(Model =c("RNN", "LSTM"),MSE =c(RNN_result[[1]],RNN_result[[2]]),MAE =c(LSTM_result[[1]], LSTM_result[[2]]))library(gt)# Create a gt tableresults_df |>gt() |>tab_header(title ="Model Performance Metrics",subtitle ="Comparison of MSE and MAE for RNN and LSTM" ) |>fmt_number(columns =vars(MSE, MAE),decimals =6 ) |>cols_label(Model ="Model Type",MSE ="Mean Squared Error",MAE ="Mean Absolute Error" ) |>tab_options(table.font.size =14,heading.title.font.size =16,heading.subtitle.font.size =14 )
Model Performance Metrics
Comparison of MSE and MAE for RNN and LSTM
Model Type
Mean Squared Error
Mean Absolute Error
RNN
0.622324
0.790441
LSTM
0.637329
0.735569
Kết quả cho thấy mô hình LSTM đưa ra kết quả tốt hơn RNN với độ sai số thấp hơn nhưng nếu bạn để ý thì thấy trong biểu đồ mình vẫn để % âm để dễ phân biệt giữa việc outstock và high inventory (bởi vì bạn đang dự báo cho nhu cầu của khách hàng). Bạn có thể so sánh thêm 1 bước nữa về tổng chi phí giữa 2 mô hình về outstock và holding cost để có cái nhìn tổng quan nhất.
Nếu bạn để ý, thực chất code cho mô hình cho như mình đã trình bày thì khá đơn giản và điều khó nhất trong mô hình là xác định số lớp layer trong mô hình. Như bài toán time series forecasting thì mình chỉ cần 2,3 lớp layer đơn giản là đã đạt kết quả tốt với sai số rất thấp (< 0.03), còn với các bài toán phức tạp hơn thì số layer sẽ nhiều hơn.
Vậy quy tắc xác định mô hình là như thế nào ? Câu trả lời là không có quy tắc nào cả và chỉ có các tips mà mình lụm nhặt trên mạng như sau:
2.5.1 Number of layer:
Số layer nên nằm giữa số input và số output. Như bài thực hành trên thì số layer nên nằm trong khoảng (1,12). Hoặc bạn có thể sử dụng hàm dưới đây để xác định.
\[
N_h = \frac{N_s}{\alpha \cdot (N_i + N_o)}
\]
Với các tham số gồm:
\(N_h\) là số lượng hidden neurons.
\(N_s\) là số lượng mẫu trong training data.
\(\alpha\) là yếu tố tỷ lệ tùy ý (thường từ 2-10).
\(N_i\) là số lượng nơ-ron input
\(N_o\) là số lượng nơ-ron output.
Ví dụ như ở mô hình trên thì số hidden layer sẽ khoảng 1-4 layer là ổn (Như trên thì mình dùng 1 layer cho mô hình RNN, 2 layer cho mô hình LSTM)
2.5.2 Choose acvtivation function:
Các hàm activation dùng để tính weighted sum và mỗi layer sẽ cần có 1 hoặc nhiều hàm để tính. Việc lựa chọn hàm ảnh hưởng lớn đến performance của mô hình, thường sẽ được chia thành 3 phần là:
Activation for input layer: thường ko dùng hàm gì cả. Bạn chỉ thực hiện processing dữ liệu để training.
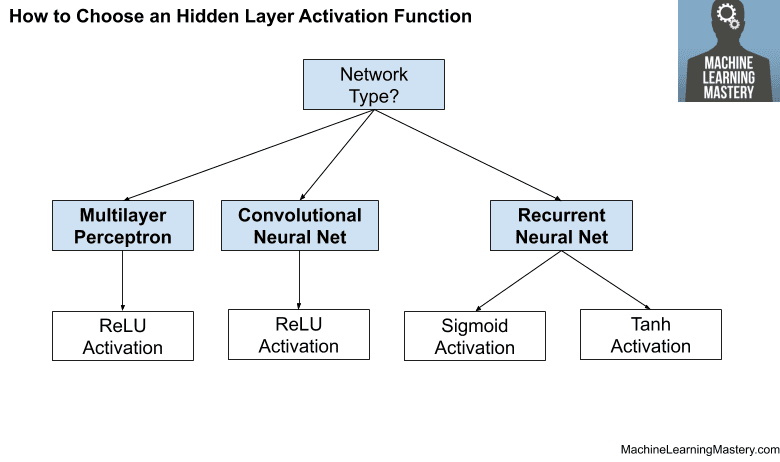
Activation for Hidden Layers:
Thông thường, hàm Tanh thì phù hợp cho dự báo giá trị liên tục từ dữ liệu chuỗi, ReLU giúp cho quá trình training nhanh hơn và không gây ra vanishing problem do không bị chặn, Softmax thường dùng ở output layer cho bài toán classification, Sigmoid thường dùng cho hồi quy logic. Ngoài ra, cách đơn giản hơn là tùy vào loại mô hình bạn đang xây dựng để lựa chọn, ví dụ như tips dưới đây mình tìm hiểu được:
Đối với output layer, bạn sẽ lựa chọn hàm dựa trên class của output mà bạn đang hướng đến. Các hàm thông thường sẽ gồm:
Linear: hay còn gọi là “identity” (nhân với 1.0) hoặc “no activation” bởi vì hàm linear tuyến tính không thay đổi weighted sum của input theo bất kỳ cách nào và thay vào đó trả về giá trị trực tiếp. Hàm này thường dùng cho output dạng liên tục.
Logistic (Sigmoid): áp dụng cho output dạng [0,1] hay còn gọi là binary classification (ví dụ mô hình nhằm đưa ra quyết định có/không trong việc đầu tư vào cổ phiểu này chẳng hạn).
Softmax: Hàm này sẽ chuyển đổi một vector thành các giá trị xác suất có tổng bằng 1 (Nó giống như tìm hàm mật độ (PDF) cho một biến). Ứng dụng để dán nhãn cho multiclass thay vì 2 class như hàm sigmoid bên trên. Mỗi nhãn sẽ có 1 giá trị xác suất và dựa vào đó dự đoán khả năng xảy ra của từng class.
2.5.3 Number of neurons:
Số lượng nơ-ron trong một lớp quyết định lượng thông tin mà mạng có thể lưu trữ. Nhiều nơ-ron giúp mạng học được các mẫu phức tạp hơn, nhưng cũng làm tăng nguy cơ overfitting (quá khớp) và yêu cầu nhiều tài nguyên tính toán hơn. Bạn có thể bắt đầu với một số lượng nơ-ron tương đối nhỏ, như 128 hoặc 256…
3 Kết luận:
Như vậy, chúng ta đã được học về mô hình RNN và LSTM và cách xây dựng chúng trong R. Tiếp theo, ta sẽ học tiếp về mô hình Transformer
Contact Me
Contact Me
Source Code
---title: "RNN and LSTM model"subtitle: "Việt Nam, 2024"categories: ["Machine Learning", "Forecasting"]format: html: code-fold: true code-tools: truenumber-sections: true---Ở đây ta sẽ học về mô hình machine learning được ứng dụng nhiều nhất trong việc phân tích dữ liệu thời gian là *RNN* và *LSTM*.## Mô hình RNN:### Định nghĩa:Điểm chung là cả hai mô hình đều thuộc phân lớp *Deep learning* - nghĩa là học máy sâu với đặc điểm chung là phân chia dữ liệu thành nhiều lớp và bắt đầu "học" dần qua từng lớp để đưa ra kết quả cuối cùng. Ở hình dưới đây, $X_o$ đại diện cho dữ liệu đầu vào, $h_t$ là output đầu ra của từng step và $A$ là những gì đã "học" được tại step đó và được truyền cho step tiếp theo. Trong tài liệu chuẩn thì họ thường kí hiệu là $X_t$, $Y_t$, $h_{t-1}$.```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/RNN.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 1: Minh họa về sự phân chia dữ liệu thành nhiều lớp </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://dominhhai.github.io/vi/2017/10/what-is-lstm/" target="_blank">Link to Image</a> </div></div>```Khi nhìn hình thì bạn có thể bối rối chưa hiểu các kí tự và hình ảnh thì bạn có thể tưởng tượng **học máy** như 1 đứa trẻ và để nó có thể hiểu được câu: "Hôm nay con đi học" thì nó phải học từng chữ cái như: a,b,c,... trước ròi mới ghép thành từ đơn như: "Hôm","Nay",... rồi ghép thành câu trên.Vậy giả sử như hôm nay học được từ "Hôm" thì nó sẽ bắt đầu ghi nhớ từ đã học vào trong $A$. Nếu sau này ta cần **học máy** hiểu câu "Hôm sau con đi chơi" thì tốc độ học của **học máy** sẽ nhanh lên vì thay vì nó phải học 5 chữ đơn như thông thường thì nó chỉ cần học 4 chữ còn lại trừ chữ "hôm". Vậy bạn đã hiểu ý tưởng nền tảng của *RNN* rồi ha!### Nguyên lí hoạt động:Đầu tiên, *RNN* sẽ tính toán *hidden state* là $h_t$ với công thức là:$$ \mathbf{h}_t = \text{activation}(\mathbf{W}_\text{hh} \mathbf{h}_{t-1} + \mathbf{W}_\text{xh} \mathbf{x}_t + \mathbf{b}_\text{h})$$Sau đó, $h_t$ sẽ được làm input cho các *state* sau và dựa vào đó để tính output với công thức là:$$y_t = W_y \cdot h_t + b_y$$**Ví dụ:** Mình muốn dự đoán hành động trong câu nói "I am reading book" bằng mô hình *RNN* như sau:- *Bước 1*: Chuyển đổi thành dạng số bằng *embedding layer*:Mình sẽ gán từng từ đơn sang dạng số như:- "I" -\> $x_1$- "am" -\> $x_2$- "reading" -\> $x_3$- "book" -\> $x_4$- *Bước 2:* Thêm hidden layer và bắt đầu tính toán:Cho input: "I"$$ h_1 = \tanh(W_x \cdot x_1 + W_h \cdot h_0 + b)$$Cho input: "am"$$ h_2 = \tanh(W_x \cdot x_2 + W_h \cdot h_1 + b)$$Cho input: "reading"$$ h_3 = \tanh(W_x \cdot x_3 + W_h \cdot h_2 + b)$$Cho input: "book"$$ h_4 = \tanh(W_x \cdot x_4 + W_h \cdot h_3 + b)$$- *Bước 3:* Tính toán output: Dùng hàm activation **softmax** để phân lớp theo xác suất.$$\hat{y} = \text{softmax}(W_y \cdot h_4 + b_y)$$Nếu muốn hiểu thêm về cách hoạt động *RNN*, bạn có thể tham khảo link này: [Recurrent Neural Network: Từ RNN đến LSTM](https://viblo.asia/p/recurrent-neural-network-tu-rnn-den-lstm-gGJ597z1ZX2).### Vấn đề lớn của RNN:*RNN* có 1 vấn đề lớn là *Vanishing Gradient* nghĩa là mô hình sẽ không còn "học" thêm được nữa cho dù tăng số `epochs`. Nguyên nhân vì sao như vậy thì bạn có thể tham khảo phần chứng minh của [anh Tuấn](https://nttuan8.com/bai-14-long-short-term-memory-lstm/).```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/vanishing.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 2: Vanishing Gradient Problem </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://www.superdatascience.com/blogs/recurrent-neural-networks-rnn-the-vanishing-gradient-problem" target="_blank">Link to Image</a> </div></div>```Vấn đề này sẽ làm network khó update *weight* dẫn tới thời gian học lâu và khó để đạt được output. Bạn có thể hiểu đơn giản như việc bạn học liên tục dẫn tới quá tải và *RNN* cũng không như vậy. Do đó, *RNN* chỉ học các thông tin từ *state* gần và đó là lí do ra đời *LSTM - Long short term memory.*::: callout-warning<u>Lưu ý</u>: Điều này không có nghĩa *LSTM* luôn tốt hơn *RNN* vì có những bài toán với đầu vào đơn giản thì mô hình chỉ cần học các step đầu là đã "học" đầy đủ thông tin cần thiết. Mô hình *LSTM* phổ biến với các bài toán phức tạp như tự động dịch ngôn ngữ, ghi chép lại theo giọng nói...:::### Mô hình LSTM:Có thể xem mô hình *LSTM* như biến thể của *RNN*. Về cấu trúc, *LSTM* phức tạp hơn *RNN*:```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/compare.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 3: So sánh mô hình RNN và LSTM </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://dominhhai.github.io/vi/2017/10/what-is-lstm/" target="_blank">Link to Image</a> </div></div>```Cấu trúc cơ bản gồm:- Cổng quên (Forget Gate): có tác dụng quyết định thông tin nào cần bị quên trong trạng thái ô nhớ.- Cổng nhập (Input Gate): Xác định thông tin nào cần được ghi vào trạng thái ô nhớ.- Cổng xuất (Output Gate): Quyết định thông tin nào sẽ được xuất ra từ trạng thái ô nhớ để ảnh hưởng đến dự đoán tiếp theo.Bạn có thể kham khảo thêm bài viết của [dominhhai](https://dominhhai.github.io/vi/2017/10/what-is-lstm/) về cách hoạt động của *RNN* và *LSTM* để hiểu thêm.Tiếp theo, ta sẽ bắt đầu xây dựng thử mô hình trong R.## Xây dựng mô hình:### Load dữ liệu:Đầu tiên ta sẽ load dữ liệu lại như trước. Ở đây, để đơn giản, mình chỉ xây dựng mô hình cho *product A* thôi.```{r}#| include: false#| warning: false#| message: falsepacman::p_load(janitor,tidyverse,dplyr,tidyr,magrittr,ggplot2,keras3,tensorflow,reticulate)``````{r}#| include: false# Set the start and end date for the 6-month periodstart_date <-as.Date("2024-05-01")end_date <-as.Date("2024-10-31")# Generate date rangedates <-seq.Date(start_date, end_date, by ="day")# Set a random seed for reproducibilityset.seed(42)# Create a vector of weekdays for each dateweekdays <-weekdays(dates)# Simulate sales data for Product A, B, and C based on weekday patternsproduct_a_sales <-sample(5:50, length(dates), replace =TRUE)product_b_sales <-sample(3:40, length(dates), replace =TRUE)product_c_sales <-sample(2:30, length(dates), replace =TRUE)# Adjust sales based on the weekdayfor (i in1:length(dates)) {if (weekdays[i] =="Wednesday"| weekdays[i] =="Saturday") {# High demand for Product A and B on Wednesday and Saturday product_a_sales[i] <-sample(40:70, 1) product_b_sales[i] <-sample(30:60, 1) } elseif (weekdays[i] =="Monday"| weekdays[i] =="Tuesday") {# High demand for Product C on Monday and Tuesday product_c_sales[i] <-sample(20:40, 1) }}# Create a data frame with the adjusted sales datasales_data <-data.frame(Date = dates,Weekday = weekdays,Product_A = product_a_sales,Product_B = product_b_sales,Product_C = product_c_sales)```Giả sử công ty mình đang kinh doanh 3 loại mặt hàng *product A*,*product B*,*product C* và đây là biểu đồ thể hiện nhu cầu của cả 3 mặt hàng từ tháng 5 tới tháng 10.```{r}#| warning: false#| message: falselibrary(highcharter)sales_data |>select(-Weekday) |>pivot_longer(cols =c(Product_A, Product_B, Product_C),names_to ="Product",values_to ="Sales") |>hchart("line", hcaes(x = Date, y = Sales, group = Product))```Nếu ta phân tich sâu về nhu cầu của từng mặt hàng theo thứ trong tuần, ta sẽ thấy rằng mặt hàng A, B thì bán chạy vào thứ 4 và thứ 7, còn mặt hàng C thì bán chạy vào thứ 2 và thứ 3.::: panel-tabset##### Product A:```{r}#| warning: false#| message: false#| echo: falsemA<-sales_data |>select(Date, Weekday, Product_A) # Ensure 'Weekday' is a factor with the correct ordermA$Weekday <-factor(mA$Weekday, levels =c("Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"))hcboxplot(x = mA$Product_A,var = mA$Weekday,name ="Weekday sales") |>hc_title(text ="Comparing sales data between weekday") |>hc_yAxis(title =list(text ="No.product")) |>hc_chart(type ="column")```##### Product B:```{r}#| warning: false#| message: false#| echo: falsemB<-sales_data |>select(Date, Weekday, Product_B) # Ensure 'Weekday' is a factor with the correct ordermA$Weekday <-factor(mB$Weekday, levels =c("Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"))hcboxplot(x = mB$Product_B,var = mB$Weekday,name ="Weekday sales") |>hc_title(text ="Comparing sales data between weekday") |>hc_yAxis(title =list(text ="No.product")) |>hc_chart(type ="column")```##### Product C:```{r}#| warning: false#| message: false#| echo: falsemC<-sales_data |>select(Date, Weekday, Product_C) # Ensure 'Weekday' is a factor with the correct ordermA$Weekday <-factor(mC$Weekday, levels =c("Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"))hcboxplot(x = mC$Product_C,var = mC$Weekday,name ="Weekday sales") |>hc_title(text ="Comparing sales data between weekday") |>hc_yAxis(title =list(text ="No.product")) |>hc_chart(type ="column")```:::```{r}#| warning: false#| message: false#| include: falselibrary(tidyverse)# Set the start and end date for the 6-month periodstart_date <-as.Date("2024-05-01")end_date <-as.Date("2024-10-31")# Generate date rangedates <-seq.Date(start_date, end_date, by ="day")# Set a random seed for reproducibilityset.seed(42)# Create a vector of weekdays for each dateweekdays <-weekdays(dates)# Simulate sales data for Product A, B, and C based on weekday patternsproduct_a_sales <-sample(5:50, length(dates), replace =TRUE)product_b_sales <-sample(3:40, length(dates), replace =TRUE)product_c_sales <-sample(2:30, length(dates), replace =TRUE)# Adjust sales based on the weekdayfor (i in1:length(dates)) {if (weekdays[i] =="Wednesday"| weekdays[i] =="Saturday") {# High demand for Product A and B on Wednesday and Saturday product_a_sales[i] <-sample(40:70, 1) product_b_sales[i] <-sample(30:60, 1) } elseif (weekdays[i] =="Monday"| weekdays[i] =="Tuesday") {# High demand for Product C on Monday and Tuesday product_c_sales[i] <-sample(20:40, 1) }}```Thông thường dữ liệu để *train model* trong *machine learning* thường cần trải qua bước *normalize data* nghĩa là đưa tất cả dữ liệu về chung 1 thước đo và phạm vi. Nguyên do vì điều này giúp nhiều thuật toán học máy dễ dàng hội tụ hơn. Ví dụ, các thuật toán như *k-Nearest Neighbors (KNN)* và *Support Vector Machines (SVM)* rất nhạy cảm với khoảng cách giữa các điểm dữ liệu nên nếu dữ liệu không được chuẩn hóa, thuật toán có thể ưu tiên các đặc trưng có phạm vi lớn hơn và bỏ qua các đặc trưng có phạm vi nhỏ hơn, dẫn đến hiệu suất kém. Và công thức phổ biến nhất cho chuẩn hóa là:$$\text{Normalized Value} = \frac{x - \min(x)}{\max(x) - \min(x)}$$```{r}#| warning: false#| message: false# Create a data frame with the adjusted sales datasales_data <-data.frame(Date = dates,Weekday = weekdays,Product_A = product_a_sales,Product_B = product_b_sales,Product_C = product_c_sales)# Convert the sales data to a time series (ts) object for Product Aproduct_a_ts <-ts(sales_data$Product_A, start =c(2024, 5), frequency =365)# Normalzie data:time_series_data<-scale(product_a_ts)library(highcharter)highchart() |>hc_add_series(data =as.numeric(time_series_data), type ="line", name ="Sales of Product A") |>hc_title(text ="Normalized Time Series of Product A") |>hc_xAxis(title =list(text ="Date")) |>hc_yAxis(title =list(text ="Normalized Sales")) |>hc_tooltip(shared =TRUE) |>hc_plotOptions(line =list(marker =list(enabled =FALSE)))```### Chia dữ liệu:Vậy để *train data*, mình sẽ chia bộ dữ liệu thành 3 phần:- *Training data*: dùng để huấn luyện và xây dựng mô hình.- *Evaluating data*: đánh giá mô hình vừa huấn luyện.- *Testing data*: dùng để đánh giá lại nếu muốn mô hình học lại dữ liệu```{r}#| warning: false#| message: falsesales_data <-data.frame(Date = dates,Weekday = weekdays,Product_A = product_a_sales,Product_B = product_b_sales,Product_C = product_c_sales)# Convert the sales data to a time series (ts) object for Product Atime_series_data <-scale(ts(sales_data$Product_A, start =c(2024, 5), frequency =365))create_supervised_data <-function(series, n) { series <-as.vector(series) # Convert time series object to vector data <-data.frame(series) # Initialize data frame with the original series# Create lag columnsfor (i in1:n) { lagged_column <-lag(series, i) # Get lagged values data <-cbind(data, lagged_column) # Add lagged column to the data }# Name the columns properlycolnames(data) <-c(paste0('t-', n:1), 't+1')# Remove rows with NA values (those at the start of the series due to lagging) data <-na.omit(data)return(data)}# Prepare the data with 12 input lags and 1 output (next time step)supervised_data <-create_supervised_data(time_series_data,n =50)# Step 2: Split data into training and test setstrain_size <-round(0.7*nrow(supervised_data)) # 70% for trainingval_size <-round(0.1*nrow(supervised_data)) # 10% for validationtest_size <-nrow(supervised_data) - train_size - val_size # 20% for testingtrain_data <- supervised_data[1:train_size, ]val_data <- supervised_data[(train_size +1):(train_size + val_size), ]test_data <- supervised_data[(train_size + val_size +1):nrow(supervised_data), ]# Correct column selectionx_train <-as.matrix(train_data[, 1:50]) # Input features (12 lags)y_train <-as.matrix(train_data[, 't+1']) # Target output (next time step)x_val <-as.matrix(val_data[, 1:50]) # Input features for validationy_val <-as.matrix(val_data[, 't+1']) # Actual output for validationx_test <-as.matrix(test_data[, 1:50]) # Input features for testingy_test <-as.matrix(test_data[, 't+1']) # Actual output for testing## Plot the result:library(xts)n<-quantile(sales_data$Date, probs =c(0, 0.7, 0.8,1), type =1)m1<-sales_data |>filter(Date <= n[[2]])m2<-sales_data |>filter(Date <= n[[3]] & Date > n[[2]])m3<-sales_data |>filter(Date <= n[[4]] & Date > n[[3]])demand_training<-xts(x=m1$Product_A,order.by=m1$Date)demand_testing<-xts(x=m2$Product_A,order.by=m2$Date)demand_forecasting<-xts(x=m3$Product_A,order.by=m3$Date)library(dygraphs)lines<-cbind(demand_training, demand_testing, demand_forecasting)dygraph(lines,main ="Training and testing data", ylab ="Quantity order (Unit: Millions)") |>dySeries("demand_training", label ="Training data") |>dySeries("demand_testing", label ="Testing data") |>dySeries("demand_forecasting", label ="Forecasting data") |>dyOptions(fillGraph =TRUE, fillAlpha =0.4) |>dyRangeSelector(height =20)```### Mô hình RNN:Sau đó, ta sẽ bắt đầu *train model* bằng cách tạo thêm 12 cột giá trị là giá trị quá khứ của *demand*. Bạn sẽ bắt đầu định nghĩa mô hình gồm:- *Input*: dùng hàm `layer_input(shape = input_shape)` với `input_shape` là số lượng *predictor*.- *Layer*: là các hidden layer trong mô hình thêm vào bằng hàm `layer_dense(x, units = 64, activation = 'relu')` với đối số `units` thường là bội số của 32 như 32,64,256,...- *Output*: dùng hàm `layer_dense(x, units = 1)` để định nghĩa là đầu ra chỉ có 1 giá trị.```{r}#| warning: false#| message: false#| include: falseuse_python("C:/Users/locca/AppData/Local/Programs/Python/Python310/python.exe", required =TRUE)# Define a function to build the RNN model with Simple RNNRNN_model <-function(input_shape) { inputs <-layer_input(shape = input_shape)# Simple RNN layer x <- inputs x <-layer_simple_rnn(x, units =64, activation ='tanh', return_sequences =TRUE) # First RNN layer x <-layer_simple_rnn(x, units =128, activation ='tanh') # Second RNN layer# Dense layers after RNN layers x <-layer_dense(x, units =128, activation ='relu') # Dense layer x <-layer_dense(x, units =64, activation ='relu') # Another dense layer# Output layer (for regression) x <-layer_dense(x, units =1) # Single output (next time step value) model <-keras_model(inputs, x)return(model)}# Example input shape (12 time steps input per sample)input_shape <-c(50,1)RNN_model <-RNN_model(input_shape)RNN_model |>compile(loss ='mse',optimizer =optimizer_adam(),metrics =c('mae'))# Step 5: Train the modelRNN_history <- RNN_model |>fit( x_train, y_train,epochs =50, batch_size =32,validation_data =list(x_val, y_val))RNN_result <- RNN_model |>evaluate(x_test, y_test)```Đối với các mô hình truyền thống như *linear regression* thì bạn đã quen với thông số $R^2$ để đánh giá mô hình, còn với mô hình *Machine learning* thì dùng khái niệm *loss function - hàm mất mát*. Về khái niệm, *loss function* sẽ đo lường chênh lệch giữa *predicted* và *actual* trong bộ *training data* nên khi càng tăng `epochs` nghĩa là tăng số lần học lại dữ liệu thì *loss function* sẽ tính ra giá trị càng thấp. Như mô hình trên thì mình đặt đối số `loss = mse` nghĩa là sử dụng *Mean Squared Error* để tối ưu quy trình học của học máy. Công thức như sau:$$MSE = \frac{1}{n} \sum_{i=1}^{n} (y_{\text{pred}}(i) - y_{\text{true}}(i))^2$$Còn đối số `metrics = c('mae')` nghĩa là tiêu chí khác để theo dõi và đánh giá mô hình. Vậy tại sao cần có 2 tham số đánh giá song song như vậy là vì như đã nói, nếu bạn càng tăng `epochs` thì giá trị *loss* càng thấp trong khi dùng `metrics` sẽ đưa ra đánh giá khách quan hơn về mô hình mà không phụ thuộc vào số lần `epochs`. Công thức như sau:$$\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_{\text{pred}}(i) - y_{\text{true}}(i)|$$Vậy khi chạy code, R sẽ return output như biểu đồ dưới đây là so sánh tham số của *mse* và *mae* giữa *training data* và *evaluating data*. Ý tưởng là đánh giá thử mô hình có dự đoán tốt không khi có dữ liệu mới vào.Tiếp theo, ta sẽ dùng *test data* để đánh giá mô hình vừa xây dựng. Kết quả có vẻ khá ổn vì mô hình gần như theo sát được dữ liệu của *test data*.```{r}# Step 6: Make predictionsRNN_forecast <- RNN_model |>predict(x_test)# Step 7: Combine predicted and observedplot_data <-data.frame(actual = y_test, # Actual values from the test setforecast = RNN_forecast # Forecasted values)# Step 8: Plot using Highchartshighchart() |>hc_title(text ="Time Series Forecasting with Highcharts") |>hc_xAxis(categories = plot_data$time,title =list(text ="Time") ) |>hc_yAxis(title =list(text ="Value"),plotLines =list(list(value =0,width =1,color ="gray" )) ) |>hc_add_series(name ="Actual Data",data = plot_data$actual,type ="line",color ="#1f77b4"# Blue color for actual data ) |>hc_add_series(name ="Forecast",data = plot_data$forecast,type ="line",color ="#ff7f0e"# Orange color for forecast data ) |>hc_tooltip(shared =TRUE,crosshairs =TRUE ) |>hc_legend(enabled =TRUE )```### Mô hình LSTM:Tiếp theo, ta sẽ xây dựng thử mô hình *LSTM*. Mô hình LSTM thường bao gồm các lớp sau:- Lớp LSTM: Đây là lớp chính, có thể có một hoặc nhiều lớp LSTM chồng lên nhau. Mỗi lớp LSTM có thể trả về toàn bộ chuỗi bằng `return_sequences = TRUE` hoặc chỉ trả về giá trị cuối cùng bằng `return_sequences = FALSE`.- Lớp Dense: Sau khi thông tin được xử lý qua các lớp LSTM, nó sẽ được đưa qua các lớp Dense (lớp fully connected) để đưa ra dự đoán cuối cùng.- Lớp Dropout (tùy chọn): Để tránh overfitting, có thể thêm lớp dropout để tắt ngẫu nhiên một số nơ-ron trong quá trình huấn luyện.```{r}#| warning: false#| message: false#| include: false# Load necessary librariesLSTM_model <-keras_model_sequential() %>%layer_lstm(units =64, input_shape =c(50, 1), return_sequences =TRUE) %>%layer_dropout(rate =0.3) %>%layer_lstm(units =32, return_sequences =FALSE) %>%layer_dropout(rate =0.3) %>%layer_dense(units =32) %>%layer_dropout(rate =0.2) %>%layer_dense(units =1)early_stop <-callback_early_stopping(monitor ="val_loss", patience =10, restore_best_weights =TRUE)model_checkpoint <-callback_model_checkpoint("best_model.keras", save_best_only =TRUE)lr_scheduler <-callback_learning_rate_scheduler(function(epoch, lr) {if (epoch >10) {return(lr *0.5) # Reduce learning rate after epoch 10 }return(lr)})LSTM_model |>compile(loss ='mse',optimizer =optimizer_adam(learning_rate =0.001),metrics =c('mae'))# Reshape the input data for LSTM (add a feature dimension)x_train <-array_reshape(x_train, dim =c(nrow(x_train), 50, 1))x_test <-array_reshape(x_test, dim =c(nrow(x_test), 50, 1))x_val <-array_reshape(x_val, dim =c(nrow(x_val), 50, 1))LSTM_model %>%fit(x_train, y_train, epochs =100, batch_size =32, validation_data =list(x_val, y_val),callbacks =list(early_stop, model_checkpoint, lr_scheduler))LSTM_result <- LSTM_model |>evaluate(x_test, y_test)```Vậy giờ ta sẽ so sánh với mô hình *RNN* trước với mô hình *LSTM* qua 2 thông số đã chọn *mse* và *mae*.```{r}#| warning: false#| message: false# Extract metrics into a data frameresults_df <-data.frame(Model =c("RNN", "LSTM"),MSE =c(RNN_result[[1]],RNN_result[[2]]),MAE =c(LSTM_result[[1]], LSTM_result[[2]]))library(gt)# Create a gt tableresults_df |>gt() |>tab_header(title ="Model Performance Metrics",subtitle ="Comparison of MSE and MAE for RNN and LSTM" ) |>fmt_number(columns =vars(MSE, MAE),decimals =6 ) |>cols_label(Model ="Model Type",MSE ="Mean Squared Error",MAE ="Mean Absolute Error" ) |>tab_options(table.font.size =14,heading.title.font.size =16,heading.subtitle.font.size =14 )```Kết quả cho thấy mô hình *LSTM* đưa ra kết quả tốt hơn *RNN* với độ sai số thấp hơn nhưng nếu bạn để ý thì thấy trong biểu đồ mình vẫn để % âm để dễ phân biệt giữa việc *outstock* và *high inventory* (bởi vì bạn đang dự báo cho nhu cầu của khách hàng). Bạn có thể so sánh thêm 1 bước nữa về tổng chi phí giữa 2 mô hình về *outstock* và *holding cost* để có cái nhìn tổng quan nhất.```{r}LSTM_forecast <- LSTM_model |>predict(x_test)compare<-data.frame(Date =1:length(y_test),LSTM =round((LSTM_forecast - y_test)/y_test,3),RNN =round((RNN_forecast - y_test)/y_test,3))# Create the highchart plot with percentage formatting for y-axishighchart() |>hc_chart(type ="line") |>hc_title(text ="Residual Comparison: LSTM vs RNN") |>hc_xAxis(categories = compare$Date,title =list(text ="Date") ) |>hc_yAxis(title =list(text ="Residuals"),labels =list(formatter =JS("function() { return (this.value).toFixed(0) + '%'; }") # Format labels as percentages ),plotLines =list(list(value =0, color ="gray", width =1, dashStyle ="Dash") ) ) |>hc_add_series(name ="LSTM Residuals",data = compare$LSTM,color ="#1f77b4" ) |>hc_add_series(name ="RNN Residuals",data = compare$RNN,color ="#ff7f0e" ) |>hc_tooltip(shared =TRUE) |>hc_legend(enabled =TRUE)```### Xác định cấu trúc mô hình:Nếu bạn để ý, thực chất code cho mô hình cho như mình đã trình bày thì khá đơn giản và điều khó nhất trong mô hình là xác định số lớp *layer* trong mô hình. Như bài toán *time series forecasting* thì mình chỉ cần 2,3 lớp layer đơn giản là đã đạt kết quả tốt với sai số rất thấp (\< 0.03), còn với các bài toán phức tạp hơn thì số *layer* sẽ nhiều hơn.Vậy quy tắc xác định mô hình là như thế nào ? Câu trả lời là **không có quy tắc nào cả** và chỉ có các tips mà mình lụm nhặt trên mạng như sau:#### Number of layer:Số *layer* nên nằm giữa số input và số output. Như bài thực hành trên thì số *layer* nên nằm trong khoảng (1,12). Hoặc bạn có thể sử dụng hàm dưới đây để xác định.$$N_h = \frac{N_s}{\alpha \cdot (N_i + N_o)}$$Với các tham số gồm:1. $N_h$ là số lượng *hidden neurons*.2. $N_s$ là số lượng mẫu trong *training data*.3. $\alpha$ là yếu tố tỷ lệ tùy ý (thường từ 2-10).4. $N_i$ là số lượng nơ-ron input5. $N_o$ là số lượng nơ-ron output.Ví dụ như ở mô hình trên thì số *hidden layer* sẽ khoảng 1-4 layer là ổn (Như trên thì mình dùng 1 layer cho mô hình RNN, 2 layer cho mô hình LSTM)#### Choose acvtivation function:Các hàm *activation* dùng để tính *weighted sum* và mỗi *layer* sẽ cần có 1 hoặc nhiều hàm để tính. Việc lựa chọn hàm ảnh hưởng lớn đến *performance* của mô hình, thường sẽ được chia thành 3 phần là:1. *Activation for input layer*: thường ko dùng hàm gì cả. Bạn chỉ thực hiện *processing* dữ liệu để training.2. *Activation for Hidden Layers*:Thông thường, hàm **Tanh** thì phù hợp cho dự báo giá trị liên tục từ dữ liệu chuỗi, **ReLU** giúp cho quá trình training nhanh hơn và không gây ra *vanishing problem* do không bị chặn, **Softmax** thường dùng ở *output layer* cho bài toán classification, **Sigmoid** thường dùng cho hồi quy logic. Ngoài ra, cách đơn giản hơn là tùy vào loại mô hình bạn đang xây dựng để lựa chọn, ví dụ như tips dưới đây mình tìm hiểu được:```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/choose.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 4: Tips chọn hàm activation cho hidden layer </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://machinelearningmastery.com/choose-an-activation-function-for-deep-learning/" target="_blank">Link to Image</a> </div></div>```3. *Activation for Output Layers*:Đối với *output layer*, bạn sẽ lựa chọn hàm dựa trên *class* của output mà bạn đang hướng đến. Các hàm thông thường sẽ gồm:- **Linear**: hay còn gọi là “identity” (nhân với 1.0) hoặc “no activation” bởi vì hàm *linear* tuyến tính không thay đổi *weighted sum* của input theo bất kỳ cách nào và thay vào đó trả về giá trị trực tiếp. Hàm này thường dùng cho output dạng liên tục.- **Logistic (Sigmoid)**: áp dụng cho output dạng \[0,1\] hay còn gọi là *binary classification* (ví dụ mô hình nhằm đưa ra quyết định có/không trong việc đầu tư vào cổ phiểu này chẳng hạn).- **Softmax**: Hàm này sẽ chuyển đổi một vector thành các giá trị xác suất có tổng bằng 1 (Nó giống như tìm hàm mật độ (PDF) cho một biến). Ứng dụng để dán nhãn cho *multiclass* thay vì 2 class như hàm *sigmoid* bên trên. Mỗi nhãn sẽ có 1 giá trị xác suất và dựa vào đó dự đoán khả năng xảy ra của từng class.#### Number of neurons:Số lượng nơ-ron trong một lớp quyết định lượng thông tin mà mạng có thể lưu trữ. Nhiều nơ-ron giúp mạng học được các mẫu phức tạp hơn, nhưng cũng làm tăng nguy cơ overfitting (quá khớp) và yêu cầu nhiều tài nguyên tính toán hơn. Bạn có thể bắt đầu với một số lượng nơ-ron tương đối nhỏ, như 128 hoặc 256...## Kết luận:Như vậy, chúng ta đã được học về mô hình *RNN* và *LSTM* và cách xây dựng chúng trong R. Tiếp theo, ta sẽ học tiếp về mô hình *Transformer*```{=html}<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Contact Me</title> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/simple-icons@v6.0.0/svgs/rstudio.svg"> <style> body { font-family: Arial, sans-serif; background-color: $secondary-color; } .container { max-width: 400px; margin: auto; padding: 20px; background: white; border-radius: 8px; box-shadow: 0 2px 10px rgba(0, 0, 0, 0.1); } label { display: block; margin: 10px 0 5px; } input[type="email"] { width: 100%; padding: 10px; margin-bottom: 15px; border: 1px solid #ccc; border-radius: 4px; } .github-button, .rpubs-button { margin-top: 20px; text-align: center; } .github-button button, .rpubs-button button { background-color: #333; color: white; border: none; padding: 10px; cursor: pointer; border-radius: 4px; width: 100%; } .github-button button:hover, .rpubs-button button:hover { background-color: #555; } .rpubs-button button { background-color: #75AADB; } .rpubs-button button:hover { background-color: #5A9BC2; } .rpubs-icon { margin-right: 5px; width: 20px; vertical-align: middle; filter: brightness(0) invert(1); } .error-message { color: red; font-size: 0.9em; margin-top: 5px; } </style></head><body> <div class="container"> <h2>Contact Me</h2> <form id="emailForm"> <label for="email">Your Email:</label> <input type="email" id="email" name="email" required aria-label="Email Address"> <div class="error-message" id="error-message" style="display: none;">Please enter a valid email address.</div> <button type="submit">Send Email</button> </form> <div class="github-button"> <button> <a href="https://github.com/Loccx78vn/RNN_model" target="_blank" style="color: white; text-decoration: none;"> <i class="fab fa-github"></i> View Code on GitHub </a> </button> </div> <div class="rpubs-button"> <button> <a href="https://rpubs.com/loccx" target="_blank" style="color: white; text-decoration: none;"> <img src="https://cdn.jsdelivr.net/npm/simple-icons@v6.0.0/icons/rstudio.svg" alt="RStudio icon" class="rpubs-icon"> Visit my RPubs </a> </button> </div> </div> <script> document.getElementById('emailForm').addEventListener('submit', function(event) { event.preventDefault(); // Prevent default form submission const emailInput = document.getElementById('email'); const email = emailInput.value; const errorMessage = document.getElementById('error-message'); // Simple email validation regex const emailPattern = /^[^\s@]+@[^\s@]+\.[^\s@]+$/; if (emailPattern.test(email)) { errorMessage.style.display = 'none'; // Hide error message const yourEmail = 'loccaoxuan103@gmail.com'; // Your email const gmailLink = `https://mail.google.com/mail/?view=cm&fs=1&to=${yourEmail}&su=Help%20Request%20from%20${encodeURIComponent(email)}`; window.open(gmailLink, '_blank'); // Open in new tab } else { errorMessage.style.display = 'block'; // Show error message } }); </script></body></html>```