Đây là bài viết của tôi về cách sử dụng R trong việc giả lập
SupplyChainManagement
Simulation
Agent Based Modeling
Author
Cao Xuân Lộc
Published
November 13, 2024
Hôm nay chúng ta sẽ qua 1 phần khác trong Supply chain management đó là: giả lập (simulation).
1 Tổng quát:
1.1 Định nghĩa:
Simulation - giả lập là một kĩ thuật máy tính nhằm tạo ra dữ liệu một cách ngẫu nhiên và dựa vào đó dự đoán quá trình phát triển, hoạt động của một sự vật, hiện tượng trong một đơn vị thời gian. Mục đích nhằm đánh giá mức độ hiệu quả của các giải pháp cho vấn đề, rủi ro trong tương lai.
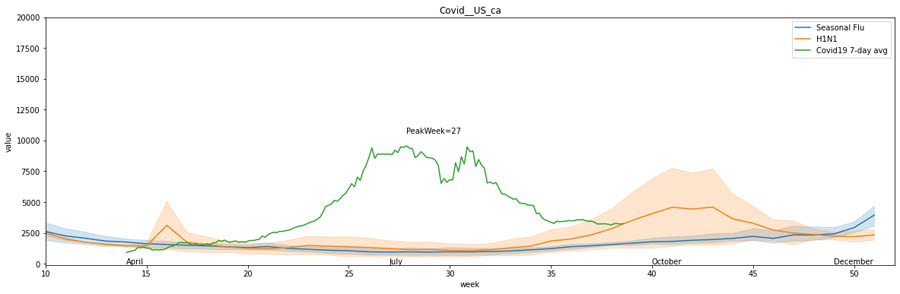
Ví dụ giả lập mà bạn gặp thường ngày như dự báo thời tiết hay dự báo tình trạng lũ lụt, sạt lở trong thời gian mưa bão. Gần đây nhất là mô hình dự đoán số ca mắc Covid-19 nhằm đánh giá mức độ lây nhiễm ở các khu vực như ảnh dưới đây là kết quả dự báo ở Mỹ.
Hình 1: Mô hình giả lập số lượng người bị nhiễm Covid-19
Thực chất nhiều đánh giá cho rằng các mô hình dự báo Covid-19 đều thất bại, tốn thời gian mà chẳng đưa ra insight gì đáng giá. Nhưng luôn nhớ rằng “All models are wrong but some are useful” - George Box nghĩa là mọi mô hình đều có sự sai lệch và nhiệm vụ của bạn là tìm ra mô hình phù hợp nhất và tạo ra giá trị trong đời thực.
Các lợi ích của việc simulation là:
Kiểm tra trực giác thống kê hoặc minh họa các đặc tính toán học mà bạn không thể dễ dàng dự đoán. Ví dụ: Kiểm tra xem liệu có hơn 5% tác động có ý nghĩa đối với một biến trong mô hình khi dữ liệu giả ngẫu nhiên được tạo ra.
Hiểu lý thuyết mẫu và phân phối xác suất hoặc kiểm tra xem bạn có hiểu các quá trình cơ bản của hệ thống của mình hay không. Ví dụ: Xem liệu dữ liệu mô phỏng lấy từ các phân phối cụ thể có thể so sánh với dữ liệu thực tế hay không.
Thực hiện phân tích độ mạnh của mẫu. Ví dụ: Đánh giá xem kích thước mẫu (trong mỗi lần lặp của mô phỏng) có đủ lớn để phát hiện tác động mô phỏng trong hơn 80% các trường hợp hay không.
Chuẩn bị kế hoạch phân tích trước. Để tự tin về các phân tích thống kê (xác nhận) mà bạn muốn thực hiện trước khi thu thập dữ liệu (ví dụ: thông qua việc đăng ký trước hoặc báo cáo đã đăng ký), việc thực hành các phân tích trên một bộ dữ liệu mô phỏng là rất hữu ích! Nếu bạn vẫn chưa chắc chắn về bài kiểm tra thống kê phù hợp nhất để áp dụng cho dữ liệu của mình, việc cung cấp bộ dữ liệu mô phỏng cho một nhà thống kê hoặc người hướng dẫn sẽ giúp họ đưa ra các gợi ý cụ thể! Mã nguồn chứa các phân tích dữ liệu mô phỏng có thể được nộp cùng với việc đăng ký trước hoặc báo cáo đã đăng ký để các nhà phản biện hiểu rõ chính xác các phân tích bạn dự định thực hiện. Khi bạn có dữ liệu thực tế, bạn chỉ cần cắm chúng vào mã này và ngay lập tức có kết quả của các phân tích xác nhận!
1.2 Phân loại:
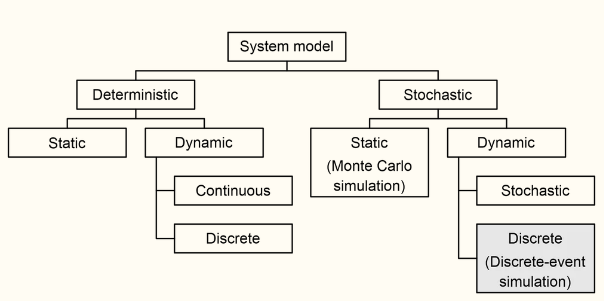
Theo lịch sự phát triển, simulation có thể được chia thành các phân lớp như sau:
2 nhánh lớn là Deterministic vs Stochastic: sự khác nhau rõ ràng nhất chính là outcome của 2 mô hình này. Đối với Deterministic thì outcome hoàn toàn dự đoán được, ví dụ với 1 lượng thông tin đầu vào như hình dạng tay chân, kích thước, màu sắc,… thì kết quả cuối cùng là phân biệt được đâu là hình ảnh của con chó hoặc con mèo và quan trọng là không có randomness từ mô hình - nghĩa là kết quả chỉ có là con chó hoặc con mèo. Còn với Stochastic thì thông tin đầu vào sẽ không rõ ràng như Deterministic - có thể là do sai lệch từ việc đo lường hoặc do chưa đủ thông tin nên outcome của nó cũng nằm trong 1 khoảng hoặc 1 tập hợp các giá trị khả thi.
2 nhánh nhỏ là Static vs Dynamic: mô hình Static thì diễn tả một quá trình mô phỏng tại 1 điểm, 1 mốc thời gian cụ thể và mô hình Dynamic cũng diễn tả như vậy nhưng quá trình mô phỏng thay đổi theo thời gian. Tiêu biểu của Static là phương pháp Monte Carlo dựa trên nền tảng về random sampling.
2 Các mô hình thông dụng trong Supply Chain Simulation:
Ứng dụng của Simulation trong Supply chain là rất nhiều, đặc biệt ở phân mảng planning. Việc giả lập trước các trường hợp, tình huống có thể gặp phải là quan trọng và nó giúp người quản lí đưa ra được các phương án thay thế hoặc phương án backup để đảm bảo chuỗi cung ứng hoạt động bình thường.
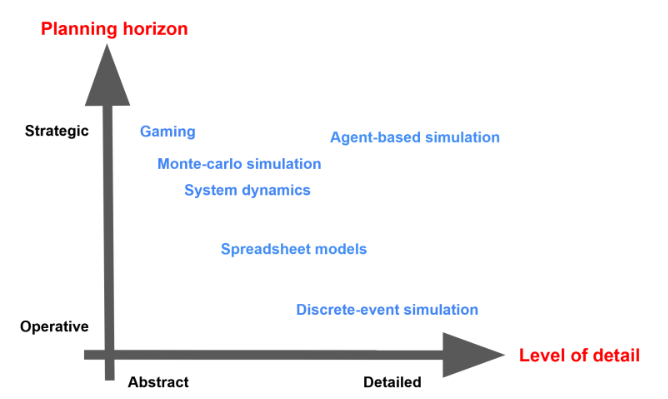
Riêng trong ngành Supply Chain thì các mô hình được sử dụng nhiều nhất bao gồm: DES - Discrete Event Simulation và ABM - Agent Based Modeling.
Hình 3: Các mô hình phổ biến trong ngành Supply Chain
DES: hướng tới mô hình hóa quy trình hoạt động của đối tượng, tựa như flowchart của process mà bạn có thể học trong quản trị vận hành. Ví dụ quá trình vận chuyển hàng từ khi có đơn bao gồm: KH đặt hàng -> CS nhận đơn và thông báo -> WH nhận thông tin đơn hàng và chuẩn bị hàng -> WH giao hàng cho Shipper -> Shipper vận chuyển đến tận nhà hoặc tới DC -> KH nhận hàng từ shipper hoặc ra DC lấy.
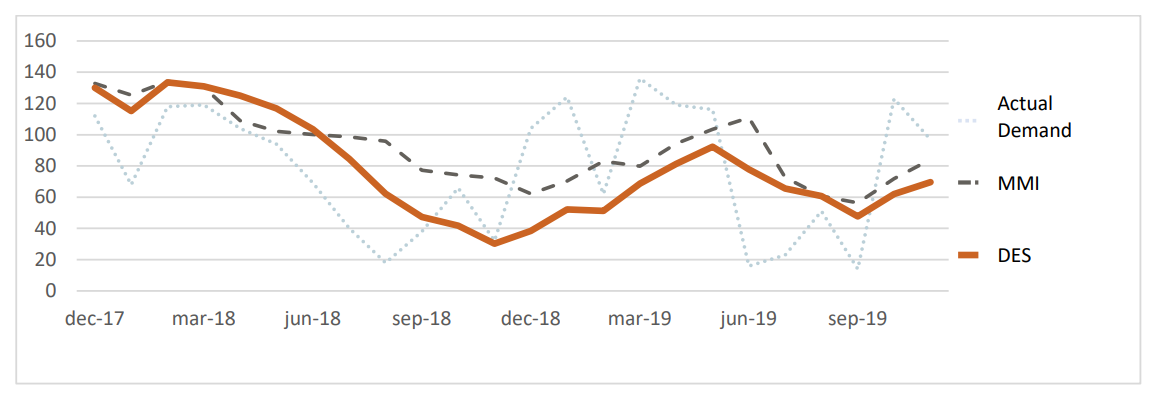
Vậy dựa vào các đặc tính đó, DES có thể giúp bạn trả lời các câu hỏi như: Khi nào xe chở hàng? ETA và ETD cụ thể bao nhiêu ?, …
Hình 4: Mô hình DES trong dự báo nhu cầu cho Volvo
ABM: là mô hình dựa vào behaviors - hành vi của từng object và đưa chúng vào enviroment để tự tương tác và thu lại dữ liệu. Về lí thuyết,ABM sẽ chi tiết và đánh giá kĩ hơn DES nên đó cũng là lý do ABM được ưu tiên sử dụng trong thời gian gần đây nhưng điều này cũng đòi hỏi độ chính xác cao về dữ liệu đầu vào để tránh sự sai lệch do độ nhạy cảm cao của mô hình này. Còn trên thực tế, mô hình nào tốt hơn còn tùy vào trường hợp mà bạn đối mặt.
Một ví dụ thực tế của mô hình ABM là trong nghiên cứu (Hiroyasu Inoue et al. 2023) về giả lập sự tác động của trận động đất GEJE nổi tiếng từng cản quết Nhật Bản đến hoạt động sản xuất của công ty.
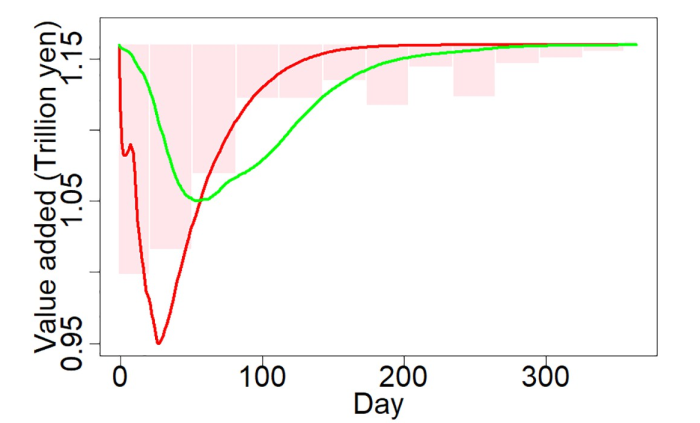
Hình 5: Mô hình ABM dự báo sự mất mát kinh tế do ảnh hưởng bởi GEJE
Mô hình trên đã giả lập sự mất mát về kinh tế (economic loss) gây bởi supply chain disruption theo thời gian tính từ lúc cơn động đất xảy ra. Đồng thời kết quả cũng cho thấy sự khác biệt so với nghiên cứu trước đây và lý do của sự chênh lệch này là việc mất điện kéo dài ảnh hưởng nặng đến hoạt động sản xuất và gây tổn thất cho ngành sản xuất Nhật Bản.
Như vậy, các bạn có thể thấy tính ứng dụng cao của simulation trong đời thực. Đối với các bài toán thực tế, tùy vào mức độ phức tạp, người dùng có thể ưu tiên ABM hay DES hoặc có thể phối hợp cả hai thuật toán này.
Vậy để việc simulation diễn ra tốt, mình sẽ cập nhập thêm các kiến thức sau đây.
2.1 Lý thuyết hàng chờ:
Đầu tiên là Queueing hay còn gọi là hàng chờ là một chuỗi các đối tượng đang chờ đợi được phục vụ và hoàn thành yêu cầu của mình từ các server trong hệ thống. Nói một cách đơn giản là giống như bạn đi mua trà sữa và đang đứng chờ tới lượt mình để order, sau đó đợi trà sữa được làm xong và lấy trà sữa và trở về nhà. Với góc nhìn của khách hàng thì không ai muốn chờ đợi, còn góc nhìn của chủ cửa hàng thì không muốn hàng chờ phải dài (mặc dù như vậy đồng nghĩa với cửa hàng đang đông khách nhưng hàng chờ dài sẽ làm khó chịu khách hàng và dẫn đến mất khách).
Như vậy, mục tiêu là: đảm bảo hàng chờ ở mức tối ưu nhất để cân bằng giữa cấp độ phục vụ (Vd: đảm bảo khách hàng hài lòng) và chi phí. Lý do vì sao mình nói rằng là tối ưu nhất chứ không phải là giảm tới mức hàng chờ = 0 là vì hàng chờ luôn luôn tồn tại cho dù bạn có tốn bao nhiêu tài nguyên vào server. Nó giống như nghịch lý quy hoạch đô thị rằng: “Xây thêm đường sẽ không giảm kẹt xe” và nghịch lý vận tải: “Đường càng rộng thì càng kẹt xe” của Matthew A. Turner và Gilles Duranton, nghĩa là bạn chỉ giảm khoảng cách của hàng kẹt xe chứ không hoàn toàn xóa bỏ tình trạng kẹt xe. Vì vậy, ví dụ nếu cửa hàng của bạn luôn tồn tại hàng chờ cỡ 5-6 người/hàng thì bạn chỉ cần thuê thêm 1 nhân viên đứng trực là hàng chờ giảm còn 2-3 người thay vì 5 nhân viên để hàng chờ giảm còn 0 bởi như vậy là tốn chi phí và không hiệu quả.
Vậy làm sao để xây dựng mô hình hàng chờ cho cửa hàng của bạn ? Đầu tiên ta cần xác định được lượng khách hàng trong một khoảng thời gian cụ thể (Vd: ngày, tuần, tháng,…) tuân theo phân bố gì, trong đó các phân bố như phân phối hàm mũ, phân phối Poisson được sử dụng phổ biến.
Code
# Load necessary libraryset.seed(123) # Define customer flow pattern for different times of the day# Morning rush: 8:30 AM - 10:30 AM# Midday: 10:30 AM - 2:00 PM# Afternoon: 2:00 PM - 4:30 PM# Evening rush: 4:30 PM - 7:00 PM# Late evening: 7:00 PM - 10:00 PM# Function to generate number of customers based on time of daygenerate_customers <-function(time) { hour <-as.numeric(format(time, "%H"))if (hour >=8&& hour <10) {# Morning rush (8:30 AM - 10:30 AM)return(sample(20:35, 1)) # 20 to 35 customers } elseif (hour >=10&& hour <14) {# Midday (10:30 AM - 2:00 PM)return(sample(20:32, 1)) # 20 to 32 customers } elseif (hour >=14&& hour <16) {# Afternoon slump (2:00 PM - 4:30 PM)return(sample(10:18, 1)) # 10 to 18 customers } elseif (hour >=16&& hour <19) {# Evening rush (4:30 PM - 7:00 PM)return(sample(30:50, 1)) # 30 to 50 customers } elseif (hour >=19&& hour <=22) {# Late evening (7:00 PM - 10:00 PM)return(sample(12:18, 1)) # 12 to 18 customers }}time_intervals<-seq(from =as.POSIXct("2024-11-11 08:30:00",tz ="UTC"),to =as.POSIXct("2024-11-11 22:00:00",tz ="UTC"),by ="30 min")# Apply the function to generate customer data for each time intervalcustomer_data <-sapply(time_intervals, generate_customers)# Create a data frame with time and customer countcoffee_data <-data.frame(Time =as.numeric(time_intervals)*1000,Customers = customer_data)library(highcharter)hchart( coffee_data,'line', hcaes(y = Customers,x = Time) ) |>hc_xAxis(title =FALSE,type ="datetime") |>hc_yAxis(title =list(text ="Number of Customers") ) |>hc_title(text ="No.Customer through a normal day in Coffee Shop")
Cách xác định là chia lượng người vào cửa hàng theo từng khoảng thời gian bằng nhau, như trên ví dụ đây là 30 phút trong khoảng thời gian hoạt động từ 8h00 AM đến 22h00 PM. Kết quả kiểm định được trình bày bên dưới với giá trị p < 0.05 cho thấy số lượng khách hàng tuân theo phân bố poisson (Mặc dù dữ liệu này được mình tạo ngẫu nhiên bởi chatGPT 😮😮😮).
Tiếp theo là xác định năng suất của server trong 1 đơn vị thời gian. Giả sử nhân viên của bạn có năng suất là như nhau và phục vụ trung bình được 1 đơn hàng/10 phút hay 6 đơn hàng/giờ thì ta có \(\mu\) = 6
Sau đó chúng ta sẽ bắt đầu quá trình giả lập và bạn có thể sử dụng 2 cách: (i) Phương pháp giải tích (giải phương trình toán học bằng tay) hoặc (ii) Phương pháp máy tính (giả lập bằng máy). Với R thì bạn hoàn toàn làm điều này dễ hơn.
Như dưới đây là ví dụ về việc giả lập thời gian phục vụ của quán cà phê với 2 hoặc 3 hoặc 4 nhân viên trực quán.
Kết quả cho thấy cửa hàng nên thuê 4 người để đảm bảo server level ở dạng cao. Nếu cửa hàng chỉ thuê 2 người thì thời gian đợi phục vụ trung bình của khách hàng là khoảng 7.5 tiếng (Một con số hơi khủng, tưởng đang sử dụng dịch vụ của Vietjet cơ! 😄😄😄) trong khi nếu thuê thêm 2 người thì giảm xuống còn 41.5 phút ~ giảm thời gian chờ đợi xuống 11 lần.
2.2 Lý thuyết thống kê:
Tiếp theo, bạn cần lý thuyết thống kê về chuyên ngành của vấn đề mà bạn đang mong muốn mô hình hóa. Việc xác định các đối tượng trong server và đối tượng mục tiêu cần giả lập cũng như các đặc tính cần có trong mô hình là quan trọng bởi chúng là sườn sống của mô hình giả lập. Ví dụ như quy trình hoạt động của quán cafe là như thế nào, sẽ hoạt động ra sao trong nhiều trường hợp,… càng rõ thì việc giả lập càng sát với thực tế.
Đặc biệt với các ngành về y sinh học, giả lập quần thể là công việc hằng ngày của các nghiên cứu sinh nên việc hiểu rõ bản chất của quần thể đó quan trọng hơn cách thức hay phương pháp giả lập.
Về code, bạn cần lưu ý rằng sample size - số lượng mẫu ảnh hưởng lớn đến độ chính xác (precision) của đo lường ảnh hưởng của biến đó. Điều này cũng tương tự với độ lặp lại (replication) nghĩa là bạn lặp lại nhiều lần việc tính toán thì kết quả sẽ tốt hoặc chính xác hơn.
---title: "Simulation"subtitle: "Việt Nam, 2024"categories: ["SupplyChainManagement", "Simulation","Agent Based Modeling"]description: "Đây là bài viết của tôi về cách sử dụng R trong việc giả lập"author: "Cao Xuân Lộc"date: "2024-11-13"title-block-banner: img/autumn.jpgtitle-block-banner-color: "white"format: html: code-fold: true code-tools: truebibliography: references.bib---Hôm nay chúng ta sẽ qua 1 phần khác trong **Supply chain management** đó là: giả lập (*simulation*).## Tổng quát:```{r}#| include: false#| message: false#| warning: falsepacman::p_load(janitor,tidyverse,dplyr,tidyr,magrittr,shiny,leaflet,reactable,leaflet.extras,ggplot2,quarto,reactablefmtr)```### Định nghĩa:**Simulation - giả lập** là một kĩ thuật máy tính nhằm tạo ra dữ liệu một cách ngẫu nhiên và dựa vào đó dự đoán quá trình phát triển, hoạt động của một sự vật, hiện tượng trong một đơn vị thời gian. Mục đích nhằm đánh giá mức độ hiệu quả của các giải pháp cho vấn đề, rủi ro trong tương lai.Ví dụ giả lập mà bạn gặp thường ngày như dự báo thời tiết hay dự báo tình trạng lũ lụt, sạt lở trong thời gian mưa bão. Gần đây nhất là mô hình dự đoán số ca mắc Covid-19 nhằm đánh giá mức độ lây nhiễm ở các khu vực như ảnh dưới đây là kết quả dự báo ở Mỹ.```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/covid19.jpg" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 1: Mô hình giả lập số lượng người bị nhiễm Covid-19 </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://pubmed.ncbi.nlm.nih.gov/33097835/" target="_blank">Link to Image</a> </div></div>```Thực chất nhiều đánh giá cho rằng các mô hình dự báo Covid-19 đều thất bại, tốn thời gian mà chẳng đưa ra *insight* gì đáng giá. Nhưng luôn nhớ rằng *"All models are wrong but some are useful" - George Box* nghĩa là mọi mô hình đều có sự sai lệch và nhiệm vụ của bạn là tìm ra mô hình phù hợp nhất và tạo ra giá trị trong đời thực.Các lợi ích của việc *simulation* là:- **Kiểm tra trực giác thống kê** hoặc minh họa các đặc tính toán học mà bạn không thể dễ dàng dự đoán. Ví dụ: Kiểm tra xem liệu có hơn 5% tác động có ý nghĩa đối với một biến trong mô hình khi dữ liệu giả ngẫu nhiên được tạo ra.- **Hiểu lý thuyết mẫu và phân phối xác suất** hoặc kiểm tra xem bạn có hiểu các quá trình cơ bản của hệ thống của mình hay không. Ví dụ: Xem liệu dữ liệu mô phỏng lấy từ các phân phối cụ thể có thể so sánh với dữ liệu thực tế hay không.- **Thực hiện phân tích độ mạnh của mẫu**. Ví dụ: Đánh giá xem kích thước mẫu (trong mỗi lần lặp của mô phỏng) có đủ lớn để phát hiện tác động mô phỏng trong hơn 80% các trường hợp hay không.- **Chuẩn bị kế hoạch phân tích trước**. Để tự tin về các phân tích thống kê (xác nhận) mà bạn muốn thực hiện trước khi thu thập dữ liệu (ví dụ: thông qua việc đăng ký trước hoặc báo cáo đã đăng ký), việc thực hành các phân tích trên một bộ dữ liệu mô phỏng là rất hữu ích! Nếu bạn vẫn chưa chắc chắn về bài kiểm tra thống kê phù hợp nhất để áp dụng cho dữ liệu của mình, việc cung cấp bộ dữ liệu mô phỏng cho một nhà thống kê hoặc người hướng dẫn sẽ giúp họ đưa ra các gợi ý cụ thể! Mã nguồn chứa các phân tích dữ liệu mô phỏng có thể được nộp cùng với việc đăng ký trước hoặc báo cáo đã đăng ký để các nhà phản biện hiểu rõ chính xác các phân tích bạn dự định thực hiện. Khi bạn có dữ liệu thực tế, bạn chỉ cần cắm chúng vào mã này và ngay lập tức có kết quả của các phân tích xác nhận!### Phân loại:Theo lịch sự phát triển, *simulation* có thể được chia thành các phân lớp như sau:```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/simulationmodel.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 2: Phân nhánh của simulation </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://softwaresim.com/blog/types-of-simulation-models-choosing-the-right-approach-for-your-simulation-project/" target="_blank">Link to Image</a> </div></div>```Trong đó:- 2 nhánh lớn là *Deterministic* vs *Stochastic*: sự khác nhau rõ ràng nhất chính là *outcome* của 2 mô hình này. Đối với *Deterministic* thì *outcome* hoàn toàn dự đoán được, ví dụ với 1 lượng thông tin đầu vào như hình dạng tay chân, kích thước, màu sắc,... thì kết quả cuối cùng là phân biệt được đâu là hình ảnh của con chó hoặc con mèo và quan trọng là không có *randomness* từ mô hình - nghĩa là kết quả chỉ có là con chó hoặc con mèo. Còn với *Stochastic* thì thông tin đầu vào sẽ không rõ ràng như *Deterministic* - có thể là do sai lệch từ việc đo lường hoặc do chưa đủ thông tin nên *outcome* của nó cũng nằm trong 1 khoảng hoặc 1 tập hợp các giá trị khả thi.- 2 nhánh nhỏ là *Static* vs *Dynamic*: mô hình *Static* thì diễn tả một quá trình mô phỏng tại 1 điểm, 1 mốc thời gian cụ thể và mô hình *Dynamic* cũng diễn tả như vậy nhưng quá trình mô phỏng thay đổi theo thời gian. Tiêu biểu của *Static* là phương pháp *Monte Carlo* dựa trên nền tảng về *random sampling*.## Các mô hình thông dụng trong Supply Chain Simulation:Ứng dụng của **Simulation** trong *Supply chain* là rất nhiều, đặc biệt ở phân mảng *planning*. Việc giả lập trước các trường hợp, tình huống có thể gặp phải là quan trọng và nó giúp người quản lí đưa ra được các phương án thay thế hoặc phương án *backup* để đảm bảo chuỗi cung ứng hoạt động bình thường.Riêng trong ngành Supply Chain thì các mô hình được sử dụng nhiều nhất bao gồm: *DES - Discrete Event Simulation* và *ABM - Agent Based Modeling*.```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/simulation.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 3: Các mô hình phổ biến trong ngành Supply Chain </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://www.supplychaindataanalytics.com/simulation-methods-for-scm-analysts/" target="_blank">Link to Image</a> </div></div>```- *DES*: hướng tới mô hình hóa quy trình hoạt động của đối tượng, tựa như flowchart của process mà bạn có thể học trong quản trị vận hành. Ví dụ quá trình vận chuyển hàng từ khi có đơn bao gồm: KH đặt hàng -\> CS nhận đơn và thông báo -\> WH nhận thông tin đơn hàng và chuẩn bị hàng -\> WH giao hàng cho Shipper -\> Shipper vận chuyển đến tận nhà hoặc tới DC -\> KH nhận hàng từ shipper hoặc ra DC lấy.Vậy dựa vào các đặc tính đó, *DES* có thể giúp bạn trả lời các câu hỏi như: Khi nào xe chở hàng? ETA và ETD cụ thể bao nhiêu ?, ...```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/DESmodel.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 4: Mô hình DES trong dự báo nhu cầu cho Volvo </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://www.diva-portal.org/smash/get/diva2:1465779/FULLTEXT02" target="_blank">Link to Image</a> </div></div>```Như hình trên này là 1 ứng dụng *DES* vào việc dự báo nhu cầu khách hàng của Volvo trong nghiên cứu của [@jagathishvarjayakumar2020].- *ABM*: là mô hình dựa vào *behaviors - hành vi* của từng object và đưa chúng vào *enviroment* để tự tương tác và thu lại dữ liệu. Về lí thuyết,*ABM* sẽ chi tiết và đánh giá kĩ hơn *DES* nên đó cũng là lý do *ABM* được ưu tiên sử dụng trong thời gian gần đây nhưng điều này cũng đòi hỏi độ chính xác cao về dữ liệu đầu vào để tránh sự sai lệch do độ nhạy cảm cao của mô hình này. Còn trên thực tế, mô hình nào tốt hơn còn tùy vào trường hợp mà bạn đối mặt.Một ví dụ thực tế của mô hình *ABM* là trong nghiên cứu [@hiroyasuinoue2023] về giả lập sự tác động của trận động đất [GEJE](https://en.wikipedia.org/wiki/2011_T%C5%8Dhoku_earthquake_and_tsunami) nổi tiếng từng cản quết Nhật Bản đến hoạt động sản xuất của công ty.```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/ABMmodel.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 5: Mô hình ABM dự báo sự mất mát kinh tế do ảnh hưởng bởi GEJE </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0288062" target="_blank">Link to Image</a> </div></div>```Mô hình trên đã giả lập sự mất mát về kinh tế (*economic loss*) gây bởi *supply chain disruption* theo thời gian tính từ lúc cơn động đất xảy ra. Đồng thời kết quả cũng cho thấy sự khác biệt so với nghiên cứu trước đây và lý do của sự chênh lệch này là việc mất điện kéo dài ảnh hưởng nặng đến hoạt động sản xuất và gây tổn thất cho ngành sản xuất Nhật Bản.Như vậy, các bạn có thể thấy tính ứng dụng cao của *simulation* trong đời thực. Đối với các bài toán thực tế, tùy vào mức độ phức tạp, người dùng có thể ưu tiên *ABM* hay *DES* hoặc có thể phối hợp cả hai thuật toán này.Vậy để việc *simulation* diễn ra tốt, mình sẽ cập nhập thêm các kiến thức sau đây.### Lý thuyết hàng chờ:Đầu tiên là *Queueing* hay còn gọi là hàng chờ là một chuỗi các đối tượng đang chờ đợi được phục vụ và hoàn thành yêu cầu của mình từ các *server* trong hệ thống. Nói một cách đơn giản là giống như bạn đi mua trà sữa và đang đứng chờ tới lượt mình để order, sau đó đợi trà sữa được làm xong và lấy trà sữa và trở về nhà. Với góc nhìn của khách hàng thì không ai muốn chờ đợi, còn góc nhìn của chủ cửa hàng thì không muốn hàng chờ phải dài (mặc dù như vậy đồng nghĩa với cửa hàng đang đông khách nhưng hàng chờ dài sẽ làm khó chịu khách hàng và dẫn đến mất khách).```{=html}<div style="text-align: center; margin-bottom: 20px;"> <img src="img/step.png" style="max-width: 100%; height: auto; display: block; margin: 0 auto;"> <!-- Picture Name --> <div style="text-align: left; margin-top: 10px;"> Hình 6: Ví dụ về queueing trong quản lí nhà kho </div> <!-- Source Link --> <div style="text-align: right; font-style: italic; margin-top: 5px;"> Source: <a href="https://chatgpt.com/" target="_blank">Link to Image</a> </div></div>```Như vậy, mục tiêu là: đảm bảo hàng chờ ở mức **tối ưu nhất** để cân bằng giữa cấp độ phục vụ (Vd: đảm bảo khách hàng hài lòng) và chi phí. Lý do vì sao mình nói rằng là **tối ưu nhất** chứ không phải là giảm tới mức hàng chờ = 0 là vì hàng chờ luôn luôn tồn tại cho dù bạn có tốn bao nhiêu tài nguyên vào *server*. Nó giống như nghịch lý quy hoạch đô thị rằng: "Xây thêm đường sẽ không giảm kẹt xe" và nghịch lý vận tải: "Đường càng rộng thì càng kẹt xe" của [Matthew A. Turner](https://vivo.brown.edu/display/mturner1) và [Gilles Duranton](https://knowledge.wharton.upenn.edu/faculty/gilles-duranton/), nghĩa là bạn chỉ giảm khoảng cách của hàng kẹt xe chứ không hoàn toàn xóa bỏ tình trạng kẹt xe. Vì vậy, ví dụ nếu cửa hàng của bạn luôn tồn tại hàng chờ cỡ 5-6 người/hàng thì bạn chỉ cần thuê thêm 1 nhân viên đứng trực là hàng chờ giảm còn 2-3 người thay vì 5 nhân viên để hàng chờ giảm còn 0 bởi như vậy là tốn chi phí và không hiệu quả.Vậy làm sao để xây dựng mô hình hàng chờ cho cửa hàng của bạn ? Đầu tiên ta cần xác định được lượng khách hàng trong một khoảng thời gian cụ thể (Vd: ngày, tuần, tháng,...) tuân theo phân bố gì, trong đó các phân bố như phân phối hàm mũ, phân phối Poisson được sử dụng phổ biến.```{r}#| warning: false#| message: false# Load necessary libraryset.seed(123) # Define customer flow pattern for different times of the day# Morning rush: 8:30 AM - 10:30 AM# Midday: 10:30 AM - 2:00 PM# Afternoon: 2:00 PM - 4:30 PM# Evening rush: 4:30 PM - 7:00 PM# Late evening: 7:00 PM - 10:00 PM# Function to generate number of customers based on time of daygenerate_customers <-function(time) { hour <-as.numeric(format(time, "%H"))if (hour >=8&& hour <10) {# Morning rush (8:30 AM - 10:30 AM)return(sample(20:35, 1)) # 20 to 35 customers } elseif (hour >=10&& hour <14) {# Midday (10:30 AM - 2:00 PM)return(sample(20:32, 1)) # 20 to 32 customers } elseif (hour >=14&& hour <16) {# Afternoon slump (2:00 PM - 4:30 PM)return(sample(10:18, 1)) # 10 to 18 customers } elseif (hour >=16&& hour <19) {# Evening rush (4:30 PM - 7:00 PM)return(sample(30:50, 1)) # 30 to 50 customers } elseif (hour >=19&& hour <=22) {# Late evening (7:00 PM - 10:00 PM)return(sample(12:18, 1)) # 12 to 18 customers }}time_intervals<-seq(from =as.POSIXct("2024-11-11 08:30:00",tz ="UTC"),to =as.POSIXct("2024-11-11 22:00:00",tz ="UTC"),by ="30 min")# Apply the function to generate customer data for each time intervalcustomer_data <-sapply(time_intervals, generate_customers)# Create a data frame with time and customer countcoffee_data <-data.frame(Time =as.numeric(time_intervals)*1000,Customers = customer_data)library(highcharter)hchart( coffee_data,'line', hcaes(y = Customers,x = Time) ) |>hc_xAxis(title =FALSE,type ="datetime") |>hc_yAxis(title =list(text ="Number of Customers") ) |>hc_title(text ="No.Customer through a normal day in Coffee Shop")```Cách xác định là chia lượng người vào cửa hàng theo từng khoảng thời gian bằng nhau, như trên ví dụ đây là 30 phút trong khoảng thời gian hoạt động từ 8h00 AM đến 22h00 PM. Kết quả kiểm định được trình bày bên dưới với giá trị p \< 0.05 cho thấy số lượng khách hàng tuân theo phân bố poisson (Mặc dù dữ liệu này được mình tạo ngẫu nhiên bởi chatGPT 😮😮😮).```{r}#| warning: false#| message: false#| include: false# Table of observed frequenciesobs_freq <-table(coffee_data$Customers)# Expected frequencies based on Poisson distributionlambda <-mean(coffee_data$Customers)exp_freq <-dpois(as.numeric(names(obs_freq)), lambda) *length(data)# Perform Chi-squared testresult <-chisq.test(obs_freq, p = exp_freq, rescale.p =TRUE)# Create a data frame for gt()result_df <-data.frame(Metric =c("Chi-squared Statistic", "Degrees of Freedom", "p-value"),Value =c(round(result$statistic,4), result$parameter, format(result$p.value, scientific =TRUE, digits =2)))counts_df <-data.frame(Category =as.numeric(names(obs_freq)),Observed =as.vector(obs_freq),`P-value`=round(exp_freq,4))```::: panel-tabset### Count table:```{r}#| warning: false#| message: falselibrary(gt)# Print Observed vs. Expected Counts Tablegt(counts_df) %>%tab_header(title ="Observed Counts vs P-value" ) %>%tab_spanner(label ="Counts",columns =c("Observed", "P.value") ) %>%tab_style(style =list(cell_text(weight ="bold") ),locations =cells_column_labels(columns =everything()) )```### Chi-squared test:```{r}# Print Chi-squared Test Results Tablegt(result_df) %>%tab_header(title ="Chi-squared Test Results" ) %>%tab_spanner(label ="Test Statistics",columns =c("Value") ) %>%tab_style(style =list(cell_text(weight ="bold") ),locations =cells_column_labels(columns =everything()) )```:::Tiếp theo là xác định năng suất của *server* trong 1 đơn vị thời gian. Giả sử nhân viên của bạn có năng suất là như nhau và phục vụ trung bình được 1 đơn hàng/10 phút hay 6 đơn hàng/giờ thì ta có $\mu$ = 6Sau đó chúng ta sẽ bắt đầu quá trình giả lập và bạn có thể sử dụng 2 cách: (i) Phương pháp giải tích (giải phương trình toán học bằng tay) hoặc (ii) Phương pháp máy tính (giả lập bằng máy). Với **R** thì bạn hoàn toàn làm điều này dễ hơn.Như dưới đây là ví dụ về việc giả lập thời gian phục vụ của quán cà phê với 2 hoặc 3 hoặc 4 nhân viên trực quán.```{r}#| include: false#| warning: false#| message: falselibrary(simmer)simulate_shop <-function(employee) { labor_capacity <-12/60# Service rate per minute# Initialize the simulation sim <-simmer("CoffeeShop")# Define the customer process customer_process <-trajectory("customer") %>%seize("barista", 1) %>%timeout(function() rexp(1, rate = labor_capacity)) %>%release("barista", 1)# Add barista resource to the simulation sim <- sim %>%add_resource("barista", capacity = employee)# Schedule customer arrivals start_time <-as.numeric(time_intervals[1]) # Convert start time to POSIX numeric customer_id <-1# Initialize a counter for unique customer namingfor (j in1:length(customer_data)) { num_customers <- customer_data[j] interval_start <-as.numeric(time_intervals[j]) # Start of each 30-min interval in POSIX numericfor (k in1:num_customers) { arrival_offset <-runif(1, 0, 1800) # Random arrival within 30 mins arrival_time <- interval_start + arrival_offset # Actual arrival time in POSIX numeric# Convert to relative time (in minutes) from start_time relative_arrival <- (arrival_time - start_time) /60# Generate a unique name for each customer customer_name <-paste0("customer_", customer_id) customer_id <- customer_id +1# Increment the unique ID# Add customer generator with a unique name sim <- sim %>%add_generator(customer_name, customer_process, at(relative_arrival)) } }# Run the simulation from 8:30 AM to 10:00 PM means 28 periods of 30 minutes sim %>%run(until = (22-8) *2*60)return(sim)}sim2<-simulate_shop(2)sim3<-simulate_shop(3)sim4<-simulate_shop(4)```::: panel-tabset### 2 employee:```{r}#| echo: falsearrival_data <- sim2 %>%get_mon_arrivals() arrival_data<-arrival_data |> dplyr::select(c(start_time, end_time, activity_time)) |>pivot_longer(cols =everything(),values_to ="time",names_to ="type")highcharter::hchart( arrival_data,'line', hcaes(y = time, group = type)) |>hc_tooltip(pointFormat ='{point.x: %Y-%m-%d} ',headerFormat ='',useHTML =TRUE,formatter =JS("function() { var baseTime = Date.parse('2024-11-11 08:30:00 UTC'); // Base time var timeOffset = this.y * 60000; // Convert minutes to milliseconds var calculatedTime = new Date(baseTime + timeOffset); return '<b>' + this.series.name + '</b><br>' + 'Time: ' + Highcharts.dateFormat('%Y-%m-%d %H:%M:%S UTC', calculatedTime); }" ) )```### 3 employee:```{r}#| echo: falselibrary(highcharter)arrival_data <- sim3 %>%get_mon_arrivals() arrival_data<-arrival_data |> dplyr::select(c(start_time, end_time, activity_time)) |>pivot_longer(cols =everything(),values_to ="time",names_to ="type")hchart( arrival_data,'line', hcaes(y = time, group = type)) |>hc_tooltip(pointFormat ='{point.x: %Y-%m-%d} ',headerFormat ='',useHTML =TRUE,formatter =JS("function() { var baseTime = Date.parse('2024-11-11 08:30:00 UTC'); // Base time var timeOffset = this.y * 60000; // Convert minutes to milliseconds var calculatedTime = new Date(baseTime + timeOffset); return '<b>' + this.series.name + '</b><br>' + 'Time: ' + Highcharts.dateFormat('%Y-%m-%d %H:%M:%S UTC', calculatedTime); }" ) )```### 4 employee:```{r}#| echo: falsearrival_data <- sim4 %>%get_mon_arrivals()library(highcharter)arrival_data |> dplyr::select(c(start_time, end_time, activity_time)) |>pivot_longer(cols =everything(),values_to ="time",names_to ="type") |>hchart('line', hcaes(y = time,group = type) ) |>hc_tooltip(pointFormat ='{point.x: %Y-%m-%d} ',headerFormat ='',useHTML =TRUE,formatter =JS("function() { var baseTime = Date.parse('2024-11-11 08:30:00 UTC'); // Base time var timeOffset = this.y * 60000; // Convert minutes to milliseconds var calculatedTime = new Date(baseTime + timeOffset); return '<b>' + this.series.name + '</b><br>' + 'Time: ' + Highcharts.dateFormat('%Y-%m-%d %H:%M:%S UTC', calculatedTime); }" ) )```:::Kết quả cho thấy cửa hàng nên thuê 4 người để đảm bảo *server level* ở dạng cao. Nếu cửa hàng chỉ thuê 2 người thì thời gian đợi phục vụ trung bình của khách hàng là khoảng **7.5 tiếng** (Một con số hơi khủng, tưởng đang sử dụng dịch vụ của Vietjet cơ! 😄😄😄) trong khi nếu thuê thêm 2 người thì giảm xuống còn **41.5 phút** \~ giảm thời gian chờ đợi xuống **11 lần**.### Lý thuyết thống kê:Tiếp theo, bạn cần lý thuyết thống kê về chuyên ngành của vấn đề mà bạn đang mong muốn mô hình hóa. Việc xác định các đối tượng trong *server* và đối tượng mục tiêu cần giả lập cũng như các đặc tính cần có trong mô hình là quan trọng bởi chúng là sườn sống của mô hình giả lập. Ví dụ như quy trình hoạt động của quán cafe là như thế nào, sẽ hoạt động ra sao trong nhiều trường hợp,... càng rõ thì việc giả lập càng sát với thực tế.Đặc biệt với các ngành về y sinh học, giả lập quần thể là công việc hằng ngày của các nghiên cứu sinh nên việc hiểu rõ bản chất của quần thể đó quan trọng hơn cách thức hay phương pháp giả lập.Về code, bạn cần lưu ý rằng *sample size - số lượng mẫu* ảnh hưởng lớn đến độ chính xác (*precision*) của đo lường ảnh hưởng của biến đó. Điều này cũng tương tự với độ lặp lại (*replication*) nghĩa là bạn lặp lại nhiều lần việc tính toán thì kết quả sẽ tốt hoặc chính xác hơn.Tiếp theo, ta sẽ thực hành trong R.```{=html}<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Go to Next Page</title> <style> /* Global Styles */ body { font-family: 'Tahoma', sans-serif; display: flex; flex-direction: column; /* Stack content and footnote vertically */ justify-content: center; /* Center content vertically */ align-items: center; /* Center content horizontally */ margin: 0; background-color: $secondary-color; box-sizing: border-box; min-height: 80vh; /* Adjusted to 80vh to ensure it's not too high */ } /* Container Styling (Main Content) */ .container { text-align: center; padding: 20px 40px; /* Adjust padding for more compactness */ background-color: white; border-radius: 12px; box-shadow: 0 8px 16px rgba(0, 0, 0, 0.1); width: auto; /* Auto width to fit content */ max-width: 380px; /* Adjusted max-width for a smaller container */ box-sizing: border-box; display: flex; justify-content: center; align-items: center; flex-direction: column; margin-top: 20px; /* Space from the top of the page */ } /* Link Styling */ .link { font-size: 20px; /* Adjusted font size for readability */ color: #007bff; text-decoration: none; font-weight: 700; display: inline-flex; align-items: center; cursor: pointer; padding: 12px 30px; border-radius: 6px; transition: all 0.3s ease; } .link:hover { color: #0056b3; text-decoration: none; background-color: #e6f0ff; } /* Arrow Styling */ .arrow { margin-left: 12px; font-size: 24px; transition: transform 0.3s ease, font-size 0.3s ease; } .link:hover .arrow { transform: translateX(8px); font-size: 26px; } /* Focus State for Accessibility */ .link:focus { outline: 2px solid #0056b3; } /* Footer Styling (Footnote) */ .footer { font-size: 14px; color: #777; margin-top: 20px; /* Space between content and footnote */ text-align: center; width: 100%; } /* Mobile-Friendly Adjustments */ @media (max-width: 600px) { .link { font-size: 18px; padding: 8px 15px; /* Smaller padding for mobile devices */ } .arrow { font-size: 18px; margin-left: 8px; } .container { padding: 15px 30px; /* Smaller padding on mobile */ max-width: 90%; /* Ensure container fits better on small screens */ } } </style></head><body> <div class="container"> <a href="https://loccx78vn.github.io/Simulation_in_R/practice.html" class="link" tabindex="0"> Go to Next Page <span class="arrow">➔</span> </a> </div></body></html>```