Code
pacman::p_load(torch,
dplyr,
tidyverse)Việt Nam, 2024
Trong một nghiên cứu của (Jimeng Shi, Mahek Jain, and Giri Narasimhan 2022) về việc ứng dụng hàng loạt các mô hình thuộc phân lớp Deep learning và so sánh để chọn ra mô hình dự đoán tốt nhất chỉ số PM2.5 (là chỉ số đo lường lượng hạt bụi li ti có trong không khí với kích thước 2,5 micron trở xuống). Kết quả có bao gồm: “Mô hình Transformer dự đoán tốt nhất cho dự đoán long-term trong tương lai. LSTM và GRU vượt trội hơn RNN cho các dự đoán short-term.”
Vậy mô hình Transformer là gì ? Chúng ta sẽ học nó ở bài này.
pacman::p_load(torch,
dplyr,
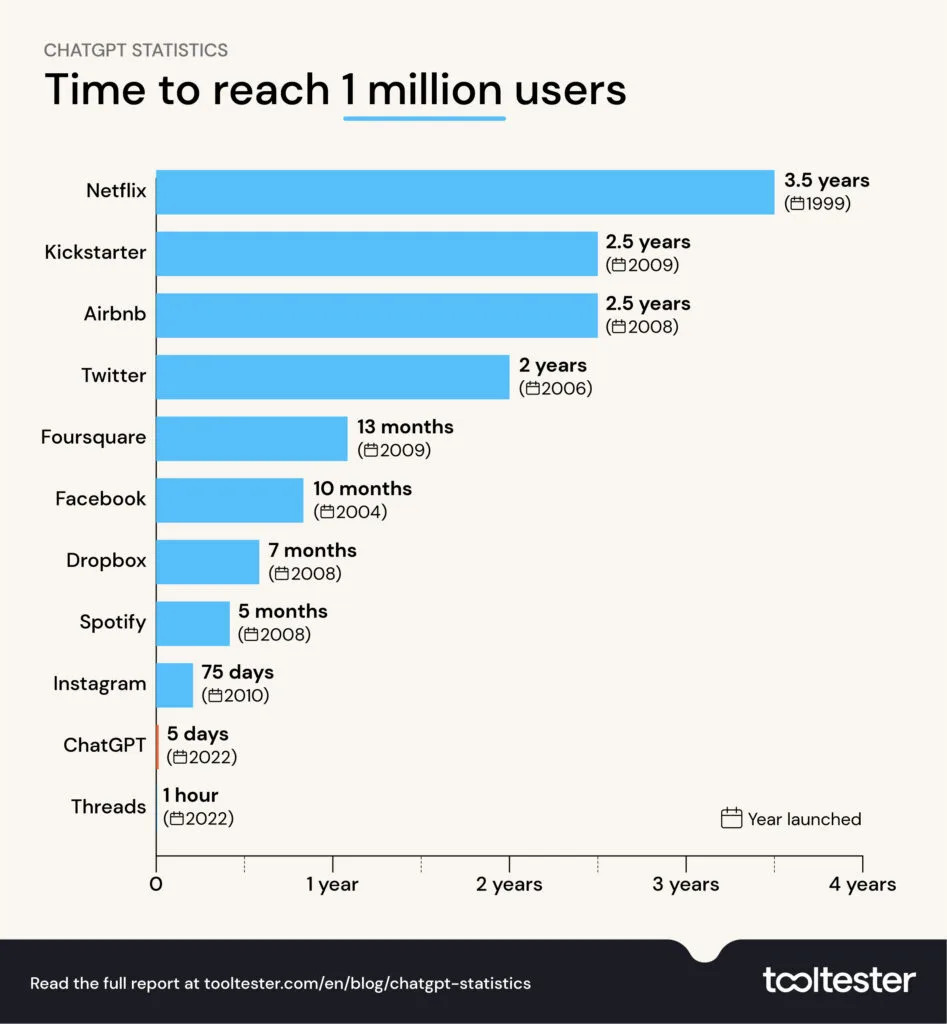
tidyverse)Chắc các bạn đã quá quen thuộc với Chatgpt - một công cụ AI mạnh mẽ trong thời gian gần đây với lượng người sử dụng cực kì cao. Như biểu đồ dưới đây, từ khi launched Chatgpt chỉ tốn 5 ngày để đạt 1 triệu người sử dụng và ngoài ra theo thống kê đến tháng 2/2024, Chatgpt đã có tới 1.6 tỉ lượt thăm quan.
Ý tưởng ban đầu của Chatgpt chính là dựa trên cấu trúc mô hình Transformer - 1 dạng Deep learning chỉ mới được giới thiệu với thế giới từ năm 2017 nhưng có sức ảnh hưởng rất lớn, nhất là trong lĩnh vực Generative AI.
Khái niệm về mô hình này được giới thiệu lần đầu vào năm 2017 của các nhà nghiên cứu của Google trong bài tài liệu Attention is all you need. Mô hình này dựa trên ý tưởng là xác định các thành phần quan trọng trong sequence và cho phép mô hình đưa ra quyết định dựa trên sự phụ thuộc giữa các phần tử trong đầu vào, bất kể khoảng cách của chúng với nhau, quá trình này gọi là Attention mechanisms. Dựa vào đó, mô hình Transformer sẽ chuyển đổi một chuỗi input thành 1 chuỗi output khác nhưng vẫn đảm bảo giữ lại các đặc điểm quan trọng của sequence đó.
Ví dụ với việc dịch thuật văn bản sẽ có những từ trong câu, câu trong đoạn văn đại diện cho ý nghĩa toàn câu, toàn đoạn văn. Hay với về việc phân tích demand trong time series, lượng mua hàng vào những ngày nghỉ, cuối tuần sẽ đưa ra insight tốt hơn vào các ngày bình thường. Như vậy, bạn thấy đó, mô hình Transformer phù hợp với các task thuộc dạng dịch văn bản, dự đoán chuỗi hành động liên tiếp của đối tượng,…
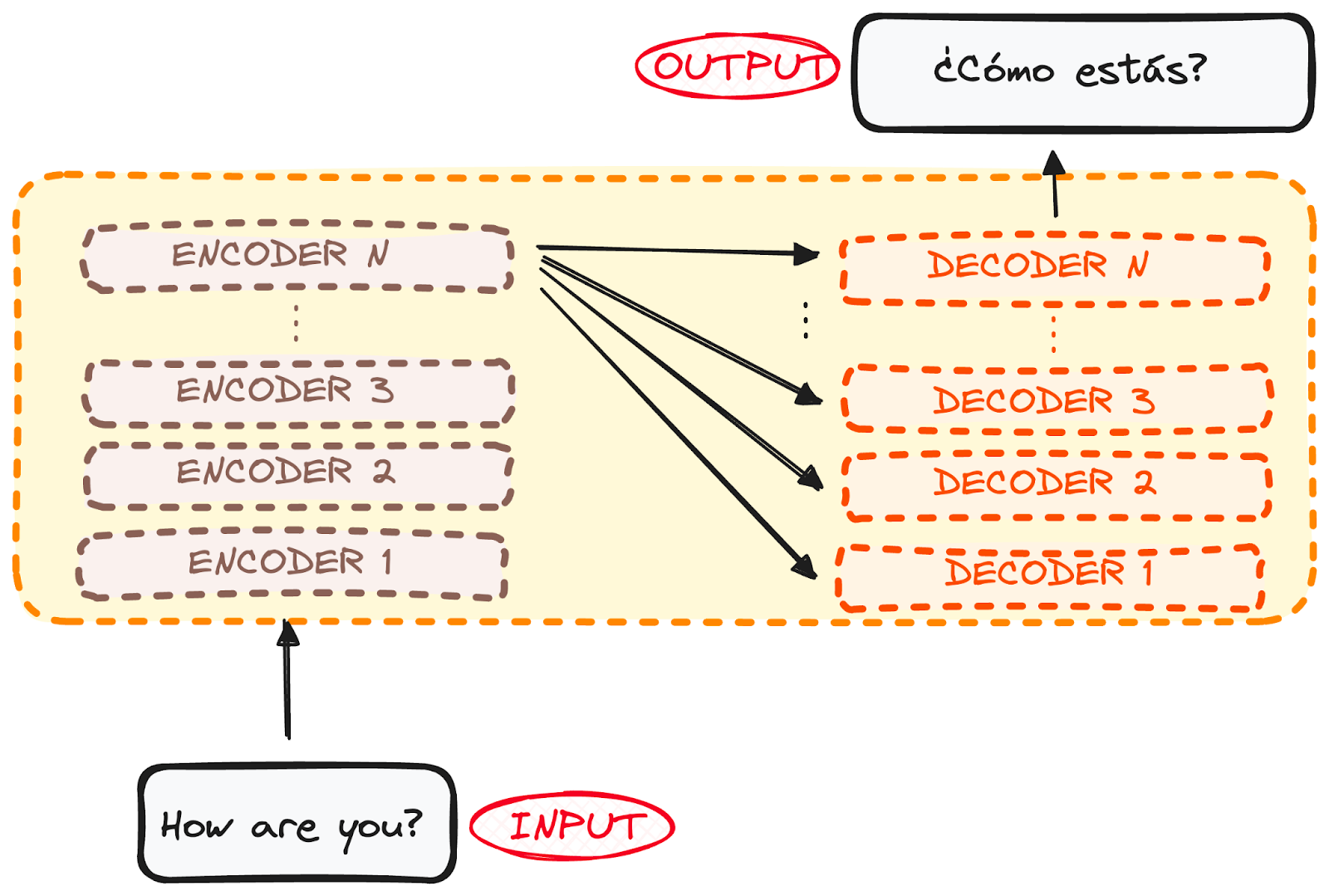
Như hình trên, bạn có thể thấy mô hình Transformer cũng gồm Encoder và Decoder giống như cách hoạt động của RNN, LSTM. Nhưng khác nhau ở chỗ, thay vì cơ chế đó hoạt động ở từng timestep liên tục nhau như RNN thì ở Transformer input được đẩy vào cùng 1 lúc (nghĩa là không còn học theo từng timestep nữa). Nhờ vậy, Transformer sẽ xác định được các thành phần quan trọng trong sequence và lựa chọn thông số cho chúng (Hiểu đơn giản như việc bạn cần nghe hết đoạn thoại của người đối diện thì mới hiểu được họ đang nói gì và chọn lọc các keyword để xác định ý chính của đoạn văn đó và đó là ý tưởng chính xây dựng lên mô hình này).
Ngoài ra, chính cơ chế Self-attention đã tạo sự khác biệt lớn cho mô hình Transformer so với các mô hình khác. Như hình dưới đây là nghiên cứu của về việc ứng dụng Deep learning để tạo phụ đề cho video. Nghiên cứu đã so sánh performance giữa 2 mô hình (i) Transformer-based model và (ii) LSTM-based model khi hyperparamater tuning. Kết quả cho thấy sự vượt trội của Transformer khi chỉ số accuracy lên tới 97%.
Tiếp theo, chúng ta sẽ tìm hiểu về các thành phần chính trong mô hình Transformer.
Về nguyên lí hoạt động, mình sẽ chia thành các phần như sau theo cách giải thích cá nhân để giúp mọi người dễ hiểu:
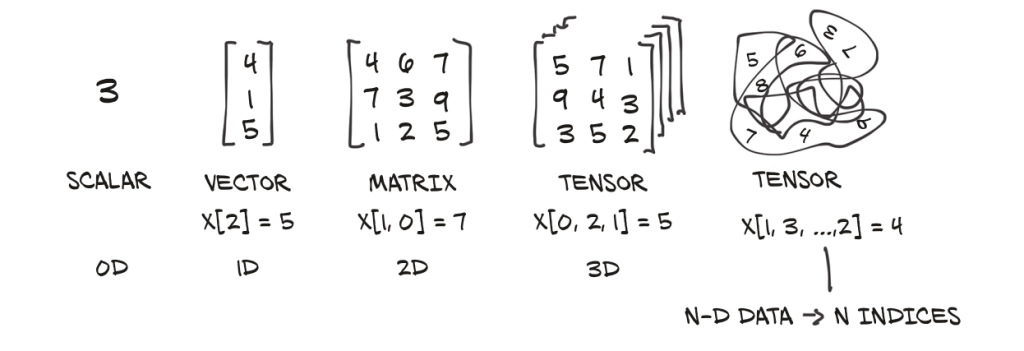
Đầu tiên, các bạn phải hiểu về tensor là gì? Thì nó là một đối tượng toán học nhằm tổng hợp hóa 1 hoặc nhiều chiều trong 1 object. Dạng đơn giản của tensor như là scalar (số đơn giản), vector (chuỗi các số),…
Và mục đích của việc chuyển đổi dữ liệu sang dạng tensor là để giúp cho việc tính toán trên GPU nhanh hơn và tăng tốc độ training machine learning model. Ngoài ra, vẫn có các thông tin khác hay về tensor trong R, bạn có thể kham khảo link này: Tensors.
Khi dữ liệu được đưa vào, nó sẽ trải qua bước embedding (cách để biểu diễn dữ liệu đa chiều trong không gian ít chiều). Nếu dữ liệu của bạn dạng hình ảnh hoặc dạng văn bản thì bước này rất cần thiết (vì các mô hình machine learning chỉ làm việc được với dữ liệu dạng số).
Ngoài ra, vì mô hình Transformer không có khả năng xử lý dữ liệu theo thứ tự tuần tự (khác với RNN hoặc LSTM), nó sẽ cần một chỉ báo để chỉ ra thứ tự của các bước trong chuỗi, gọi là Postitional encoding. Bạn có thể kham khảo bài viết của Mehreen Saeed. Và code trong R sẽ ví dự như sau:
positional_encoding <- function(seq_len, d, n = 10000) {
P <- matrix(0, nrow = seq_len, ncol = d)
for (k in 1:seq_len) {
for (i in 0:(d / 2 - 1)) {
denominator <- n^(2 * i / d)
P[k, 2 * i + 1] <- sin(k / denominator)
P[k, 2 * i + 2] <- cos(k / denominator)
}
}
return(P)
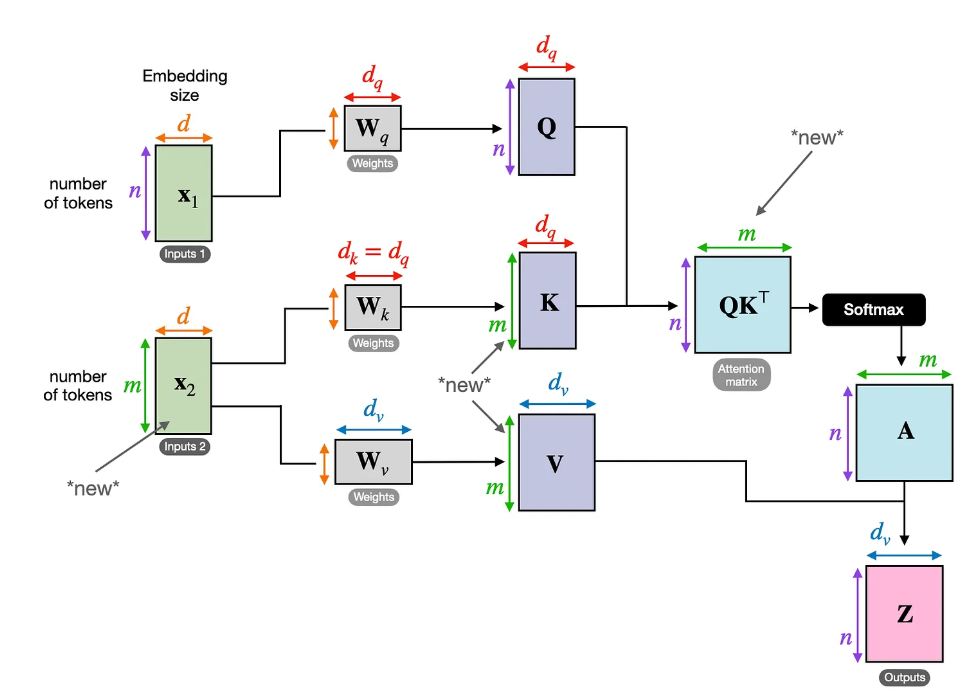
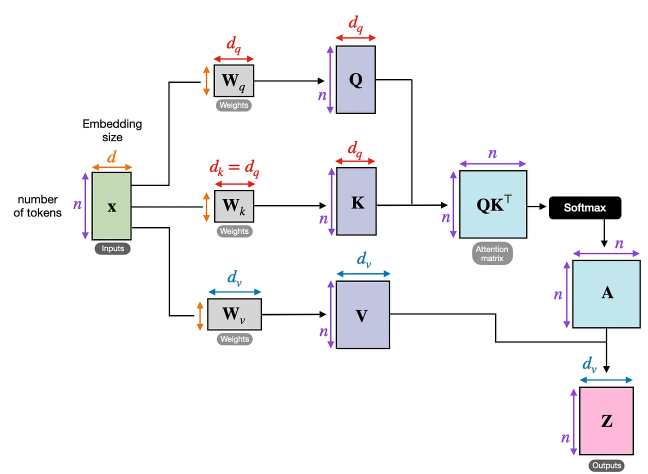
}Đây là một cơ chế đặc biệt của Transformer, cho phép mô hình chú ý đến tất cả các bước thời gian trước đó trong chuỗi tại mỗi bước. Điều này giúp mô hình nắm bắt được các mối quan hệ dài hạn và sự liên hệ giữa các bước thời gian với nhau (giúp tránh gặp vấn đề ghi nhớ ngắn hạn như RNN). Bạn có thể xem Self-attention như là cấu trúc chung nhất, còn khi xây dựng mô hình người ta có thể biến tấu tùy vào nhu cầu.
Như ở Encoder thì sử dụng Multi-Head Attention có thể tính toán chú ý nhiều lần song song (khác với self -attention chỉ tính toán cho single sequence) . Mỗi “đầu” có thể chú ý đến những khía cạnh khác nhau của các mối quan hệ thời gian trong chuỗi. Ví dụ, một đầu có thể chú ý đến các mẫu ngắn hạn (ví dụ: sự dao động hàng ngày), trong khi một đầu khác có thể nắm bắt các xu hướng dài hạn (ví dụ: chu kỳ mùa). Trong R thì đã có sẵn hàm nn_multihead_attention() trong package torch.
Còn đối với Decoder thì dùng Masked Multi-Head Attention để đảm bảo rằng khi dự báo giá trị tiếp theo trong chuỗi thời gian, mô hình chỉ có thể chú ý đến các bước thời gian trước đó mà không nhìn vào các bước thời gian tương lai. So sánh với Self-attention thì bạn cần thêm bước Masked score thôi. Trong R sẽ được code như sau:
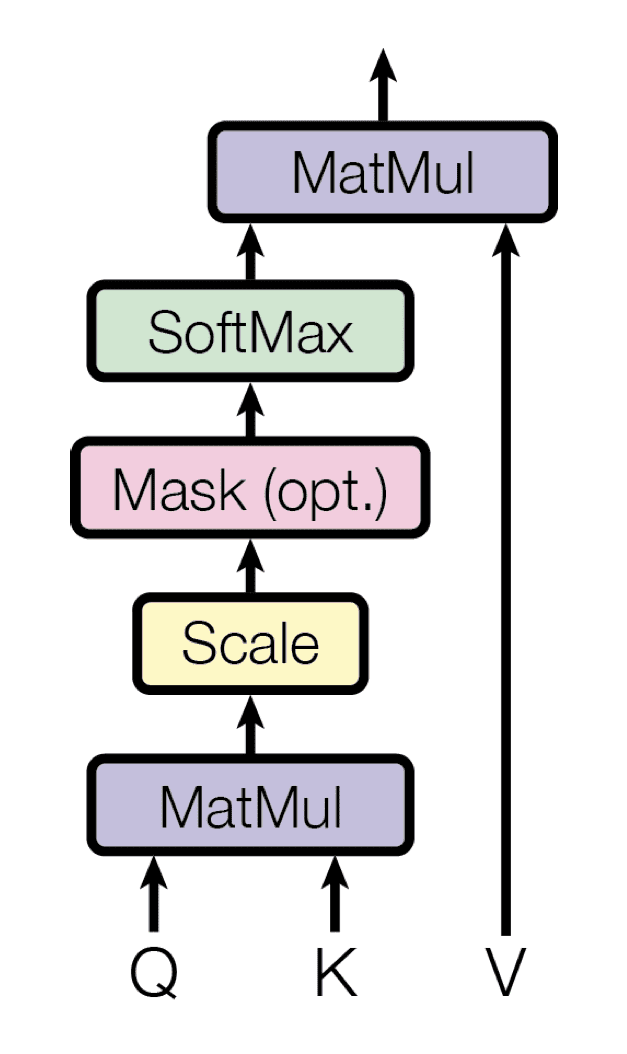
mask_self_attention <- nn_module(
initialize = function(embed_dim, num_heads) {
self$embed_dim <- embed_dim
self$num_heads <- num_heads
self$head_dim <- embed_dim / num_heads
if (embed_dim %% num_heads != 0) {
stop("embed_dim must be divisible by num_heads")
}
# Linear layers for Q, K, V
self$query <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$key <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$value <- nn_linear(embed_dim, embed_dim, bias = FALSE)
# Final linear layer after concatenating heads
self$out <- nn_linear(embed_dim, embed_dim, bias = FALSE)
},
forward = function(x) {
batch_size <- x$size(1)
seq_leng <- x$size(2)
# Linear projections for Q, K, V
Q <- self$query(x) # (batch_size, seq_leng, embed_dim)
K <- self$key(x)
V <- self$value(x)
# Reshape to separate heads: (batch_size, num_heads, seq_leng, head_dim)
Q <- Q$view(c(batch_size, seq_leng, self$num_heads, self$head_dim))$transpose(2, 3)
K <- K$view(c(batch_size, seq_leng, self$num_heads, self$head_dim))$transpose(2, 3)
V <- V$view(c(batch_size, seq_leng, self$num_heads, self$head_dim))$transpose(2, 3)
# Compute Matmul and scale:
d_k <- self$head_dim
attention_scores <- torch_matmul(Q, torch_transpose(K, -1, -2)) / sqrt(d_k)
# Apply mask if provided
mask <- torch_tril(torch_ones(c(seq_leng, seq_leng)))
if (!is.null(mask)) {
masked_attention_scores <- attention_scores$masked_fill(mask == 0, -Inf)
} else {
print("Warning: No mask provided")
}
# Compute attention weights
weights <- nnf_softmax(masked_attention_scores, dim = -1)
# Apply weights to V
attn_output <- torch_matmul(weights, V)
# Reshape again:
attn_output <- attn_output$transpose(2, 3)$contiguous()$view(c(batch_size, seq_leng, self$embed_dim))
# Final linear layer
output <- self$out(attn_output)
return(output)
}
)Ngoài ra, trong Decoder còn có Cross-attention nhưng nó hơi phức tạp nên mình sẽ giới thiệu sau.
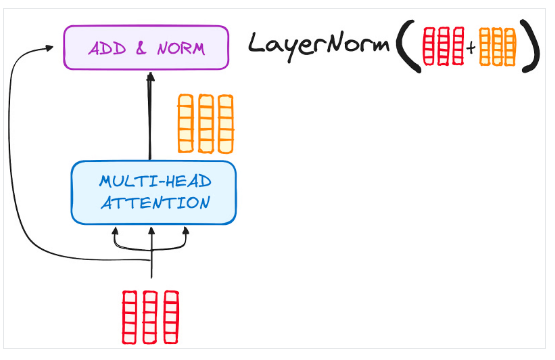
Bạn sẽ để ý thấy các phép tính toán trong mô hình sẽ luôn kèm theo bộ phận Add & Norm để lưu giữ residual và cộng vào output được tạo sau khi kết thúc các phép tính đó. Việc này giúp giảm thiểu vấn đề vanishing gradient đã đề cập ở trang trước và giúp cho mô hình học sâu hơn. Trong R bạn chỉ cần thêm lớp này bằng hàm nn_layer_norm().
Sau khi tính toán chú ý, đại diện của từng bước thời gian sẽ được đưa qua một mạng nơ-ron Feed-Forward (FFN), thường bao gồm: (i) Một phép biến đổi tuyến tính (lớp kết nối đầy đủ), (ii) Hàm kích hoạt ReLU và (iii) Một phép biến đổi tuyến tính nữa. Trong R sẽ code như này:
feed_forward <- nn_sequential(
nn_linear(d_model, d_ff),
nn_relu(),
nn_linear(d_ff, d_model)
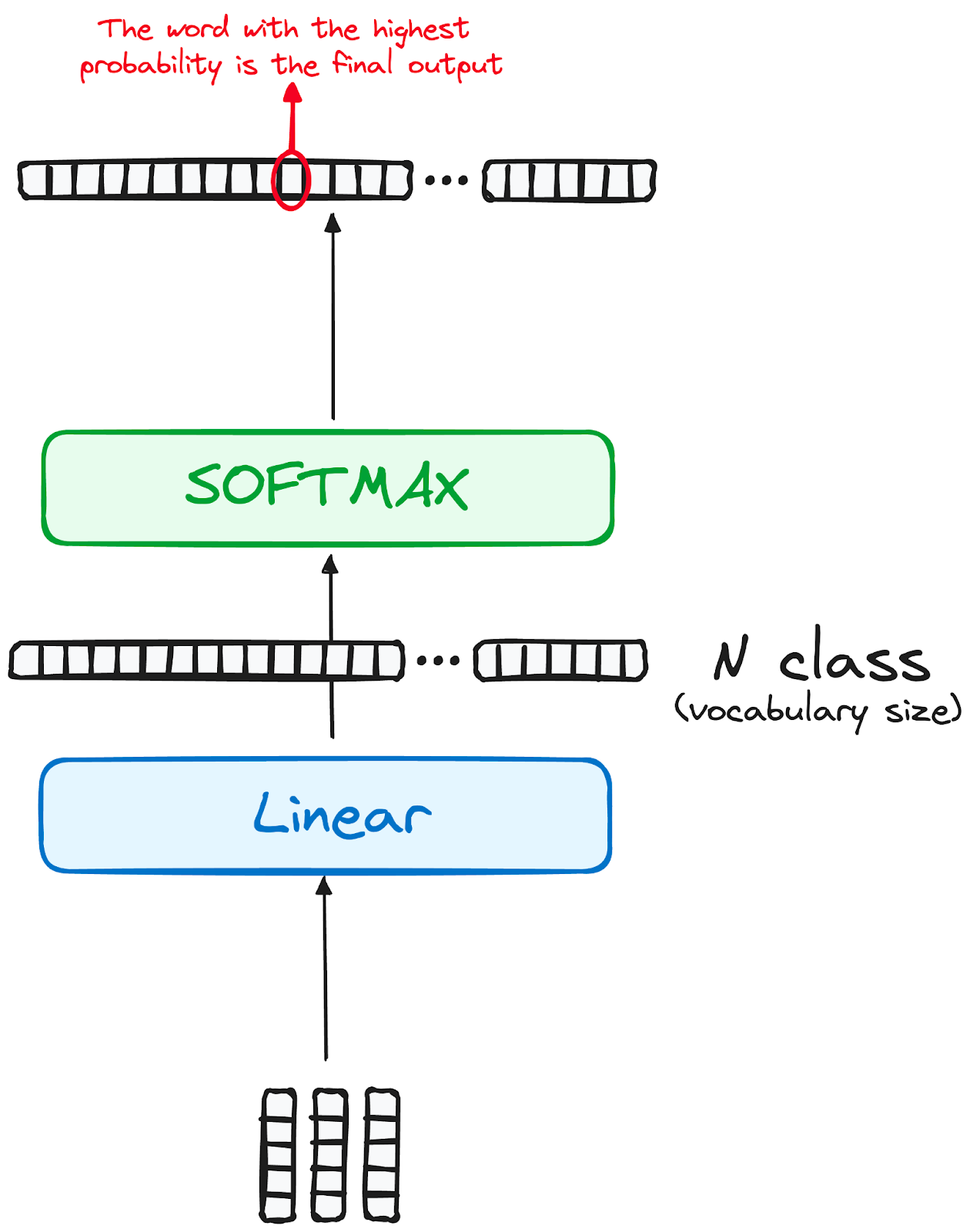
)Sau khi hiểu rõ các thành phần cần thiết, ta sẽ ngó qua workflow đầy đủ của mô hình Transformer.Nếu bạn chưa hiểu thì có thể kham khảo link này datacamp
Mình sẽ trình bày theo cách cá nhân để giúp mọi người hiểu rõ hơn:
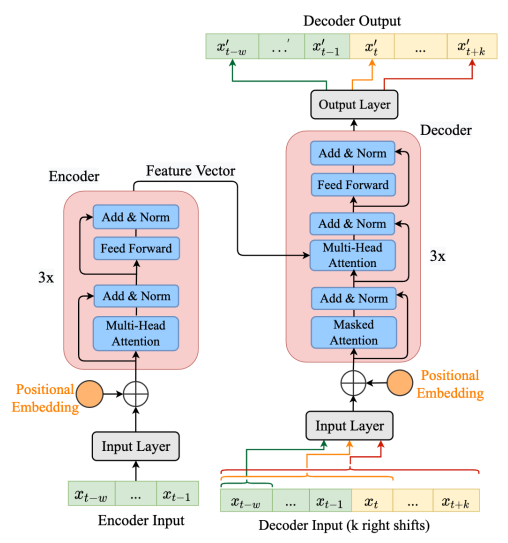
Bước 1: Xử lí input: sẽ gồm bước Embedding dữ liệu sau đó cộng thêm Positional encoding. Lưu ý: input cho encoder và decoder là khác nhau, encoder sẽ nhận đầu vào là các biến dự báo (ví dụ: giá trị lag của time series,…) và decoder sẽ nhận đầu vào là biến target (là kết quả bạn mong muốn mô hình dự báo đúng).
Bước 2: Encoder output: Khi dữ liệu đi vào encoder block thì sẽ trải qua lớp multi-head attention* và feed forward và các lớp sub-layer normalization. Lưu ý: khi normalizing thì phải normalize (kết quả từ lớp trước + input ban đầu), bạn có thể nhìn ảnh dưới đây để dễ hiểu hơn.
Vậy cross-attention có gì đặc biệt? Ta sẽ nhìn sơ qua cấu trúc của nó thì sẽ nhận ra điểm khác biệt so với self-attention thông thường là cross-attention sẽ nhận dữ liệu từ 2 nguồn: (i) output của encoder gán cho Q và (ii) input của decoder gán cho V, K.
Về code trong R sẽ như sau:
cross_attention <- nn_module(
initialize = function(embed_dim, num_heads) {
self$embed_dim <- embed_dim
self$num_heads <- num_heads
self$head_dim <- embed_dim / num_heads
if (self$head_dim %% 1 != 0) {
stop("embed_dim must be divisible by num_heads")
}
self$query <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$key <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$value <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$out <- nn_linear(embed_dim, embed_dim, bias = FALSE)
},
forward = function(decoder_input, encoder_output, mask = NULL) {
batch_size <- decoder_input$size(1)
seq_leng_dec <- decoder_input$size(2)
seq_leng_enc <- encoder_output$size(2)
Q <- self$query(decoder_input)
K <- self$key(encoder_output)
V <- self$value(encoder_output)
Q <- Q$view(c(batch_size, seq_leng_dec, self$num_heads, self$head_dim))$transpose(2, 3)
K <- K$view(c(batch_size, seq_leng_enc, self$num_heads, self$head_dim))$transpose(2, 3)
V <- V$view(c(batch_size, seq_leng_enc, self$num_heads, self$head_dim))$transpose(2, 3)
d_k <- self$head_dim
attention_scores <- torch_matmul(Q, torch_transpose(K, -1, -2)) / sqrt(d_k)
weights <- nnf_softmax(attention_scores, dim = -1)
attn_output <- torch_matmul(weights, V)
attn_output <- attn_output$transpose(2, 3)$contiguous()$view(c(batch_size, seq_leng_dec, self$embed_dim))
output <- self$out(attn_output)
return(output)
}
)Kết quả sau đó sẽ được đẩy qua layer feed forward và normalization để trả về output (giống như encoder).
Như vậy, chúng ta đã lướt sơ qua cách hoạt động và các lưu ý của mô hình Transformer. Tiếp theo, mình sẽ thử xây dựng trong R và dùng nó để xử lí task dự báo chuỗi thời gian.